

从萌芽到落地应用,隐私计算发展史




独家抢先看
随着我国数据立法进程加快,各领域对合规数据流通的需求日益强烈,隐私计算市场迎来快速发展,国家工业信息安全发展研究中心《中国隐私计算产业发展报告(2020-2021)》显示,隐私计算产品市场规模约为十亿元,基于隐私计算的数据交易应用模式市场或将达到千亿级。
联邦学习(Federated Learning)是一种分布式机器学习技术,其核心思想是通过在多个拥有本地数据的数据源之间进行分布式模型训练,在不需要交换本地个体或样本数据的前提下,仅通过交换模型参数或中间结果的方式,构建基于虚拟融合数据下的全局模型,从而实现数据隐私保护和数据共享计算的平衡,即“数据可用不可见”、“数据不动模型动”的应用新范式。其理论基础为:分布式数据库关联规则挖掘技术,主要应用于医疗、金融、电信、政务等领域。
随着人类社会数字化进程越来越快,产生了大量数据。通过机器学习技术可以自动化地挖掘数据中蕴藏的宝藏,经过大量数据训练出来的机器学习模型已经应用在各类场景中,正在深刻改变着我们的世界,例如精准医疗、临床辅助诊断、新药研发、人像识别、声纹识别、千人千面推荐算法、图片、语音、自然语言等多模态学习。在应用中,模型的精度、泛化能力等至关重要,而这些都赖于机器对大量数据的学习。
受限于法律法规、政策监管、商业机密、个人隐私等数据隐私安全上的约束,多个数据来源方无法直接交换数据,形成“数据孤岛”现象,制约着人工智能模型能力的进一步提高。联邦学习的诞生即是为了解决这一问题。
联邦学习本质上是一种分布式机器学习框架,其做到了在保障数据隐私安全及合法合规的基础上,实现数据共享,共同建模。它的核心思想是在多个数据源共同参与模型训练时,不需要进行原始数据流转的前提下,仅通过交互模型中间参数进行模型联合训练,原始数据可以不出本地。这种方式实现数据隐私保护和数据共享分析的平衡,即“数据可用不可见”的数据应用模式。
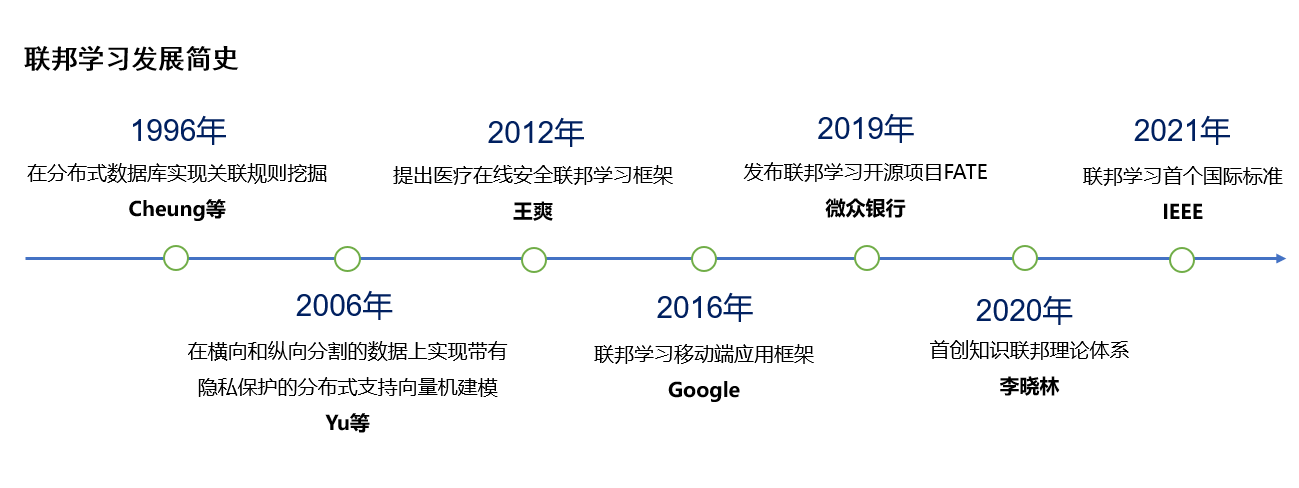
联邦学习的技术理论基础可以追溯到分布式数据库(Distributed Database)关联规则挖掘技术,1996年,Cheung等人首次提出在分布式数据库中实现关联规则(Association Rules)挖掘。
2006年,Yu等人提出了在横向和纵向分割的数据上,实现带有隐私保护的分布式支持向量机建模。
2012年,王爽教授团队首次提出分布式隐私保护下的在线机器学习等概念,并首次解决医疗在线安全联邦学习问题,该框架服务于多个国家级医疗健康网络,也是联邦学习系统构架层面的突破。
2016年,Google AI团队提出联邦学习算法框架应用于移动互联网手机终端的隐私保护。
2019年,微众银行AI团队提出联邦迁移学习,结合联邦学习和迁移学习并发布FATE开源系统。
2020年,李晓林教授首创知识联邦理论体系。
2021年3月,IEEE正式发布联邦学习首个国际标准《IEEE 3652.1-2020 - IEEE Guide for Architectural Framework and Application of Federated Machine Learning》。
联邦学习重要节点及里程碑
2012年
王爽:提出医疗在线安全联邦学习框架
2012年,王爽教授团队提交并于2013年发表在SCI学术期刊Journal of Biomedical Informatics的《Expectation Propagation Logistic Regression (EXPLORER): Distributed privacy-preserving online model learning》论文,这是目前有据可查的全球第一篇医疗在线安全联邦学习文献,论文提出了数据“可用不可见”问题,在不需要分享原始个体数据的情况下,利用多个数据源进行带有隐私保护的联合建模的概念。同年,该团队发表了开源联邦学习框架“WebGLORE: a web service for Grid Logistic Regression”,该底层技术服务于多个医疗网络数据的联邦建模需求。
2016年
Google:联邦学习移动端应用框架
2016年,Google AI团队提出联邦学习算法框架应用于移动互联网手机终端的隐私保护。该算法框架主要针对设备数据集进行协同机器学习模型训练,让数据在不离开设备的情况下,可以在多种设备上训练共享机器学习模型。2019年,Google实现了第一个产品级的移动端联邦学习系统,并把该系统从联邦学习推广到联邦计算和联邦分析。
2019年
微众银行:发布联邦学习开源项目FATE
2019年2月,微众银行AI团队对外发布自主研发的联邦学习开源项目FATE(Federated AI Technology Enabler)。FATE提供了一种带有数据隐私保护功能的分布式安全计算框架,为机器学习、迁移学习算法提供隐私计算支持。同时,FATE提供了一套跨域交互信息管理方案,提供联邦学习信息安全审计功能。
2020年
李晓林:提出知识联邦学习理论体系
2020年,李晓林教授提出知识联邦理论体系,知识联邦是一个安全多方应用框架,它支持安全多方查询、安全多方计算、安全多方学习、安全多方推理等联邦应用。知识联邦关注的是数据到知识的全生命周期隐私安全保护,包括知识创造、管理和使用及其监管,设计目标是面向生产环境的知识联邦生态系统,致力于推动人工智能发展。
2020年7月,中国信息通信研究院联合华控清交、锘崴科技、微众银行、数牍科技、同盾科技等十余家单位及企业制定了联邦学习技术标准——《基于联邦学习的数据流通产品技术要求与测试方法》,该标准规定了基于联邦学习的数据流通产品必要的技术要求及相应的测试方法,适用于基于联邦学习的数据流通产品的研发、测试、评估和验收等场景。
2022年2月,中国信息通信研究院联合卓信大数据、铸基计划、锘崴科技、百度网讯、洞见科技等多家联邦学习产业链上下游企业编写的《联邦学习场景应用研究报告(2022年)》正式发布,标志着中国隐私计算领域进入到了一个快速发展阶段。技术路径有:联邦迁移学习、安全联邦学习、知识联邦。



