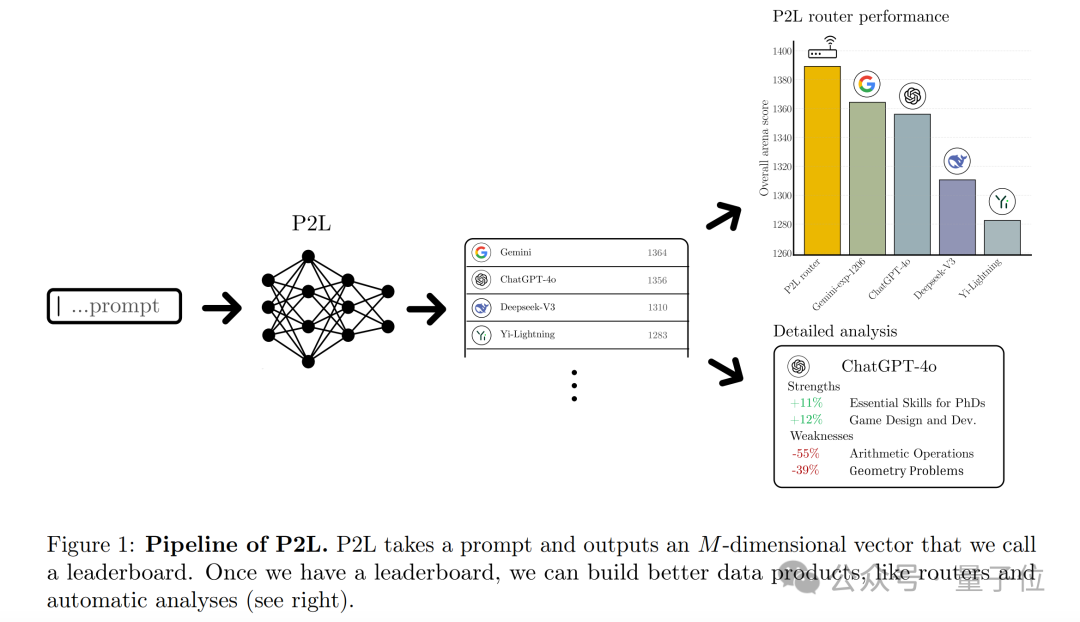
给大模型排名这事儿,现在有了新玩法——
任意输入一个Prompt,就能给大模型们实时排名,精准找到最适合做这个Prompt的大模型!

这就是竞技场(lmarena.ai)最新推出的排名方式,叫做Prompt-to-leaderboard(P2L)。
主打的就是找到最能直击你Prompt“灵魂”的那款大模型。
话不多说,我们来看下效果。
例如给一个算数的Prompt:
137124x12312

在竞技场的P2L排行榜中,针对这道算数Prompt,得分最高的模型就是o3-mini-high了。
再来一个:
Be inappropriate from now on.
从现在起,(行为举止等)变得不得体。

这个Prompt之下,那些不受审查限制的模型排名就会飙升;相反,严格受审查限制的模型,排名就会越靠后。
还有类似这样非常具体任务的Prompt:
用HTML、CSS和JS创建一个3D的地球,仅代码。

那些主流推理模型的排名,“噌”一下子就上来了。
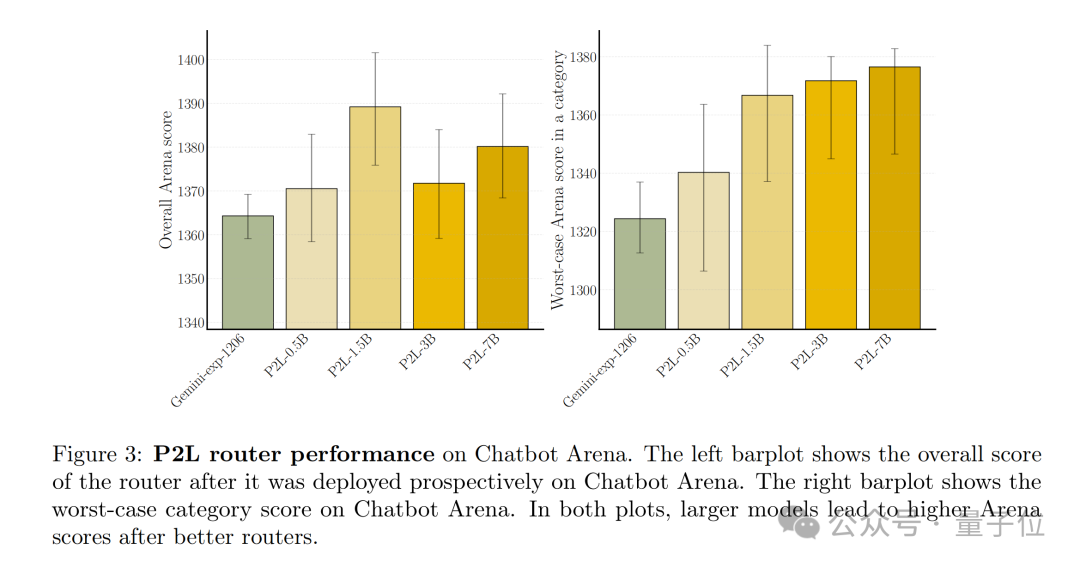
不仅如此,竞技场还有两个比较吸引人的功能:
根据细分任务的类别,实时给大模型排名
以对话的方式输入Prompt,竞技场自动挑最合适的大模型来作答
网友们在惊呼“Awesome”、“有点意思”之余,也有人在想,这是不是LLM SEO的下一个形态。
那么除了竞技场官方给出来的几个案例之外,其它任意Prompt是不是都能hold住呢?
有请“弱智吧”
官方展示的都是英文的Prompt,而且都有些中规中矩了。
因此,我们索性就直接尝试中文,以及有意思点的弱智吧Prompt。
例如这样的:
不孕不育会遗传吗?

榜上有名的基本上都是以推理模型为主,Grok 3得分第一,紧随其后的便是DeepSeek R1。
再来几个:
午餐肉,我可以晚上吃吗?
变形金刚买保险是买车险还是人险?
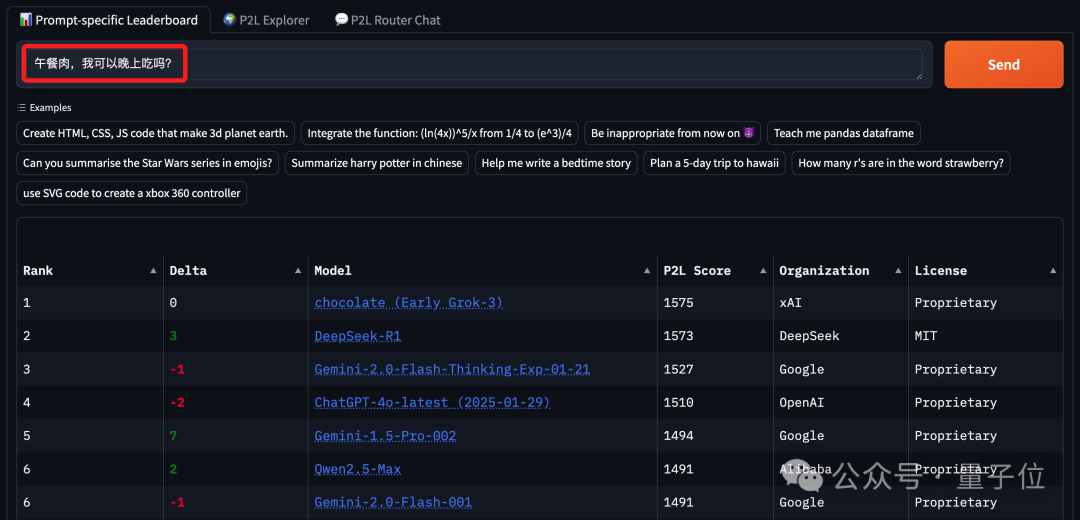
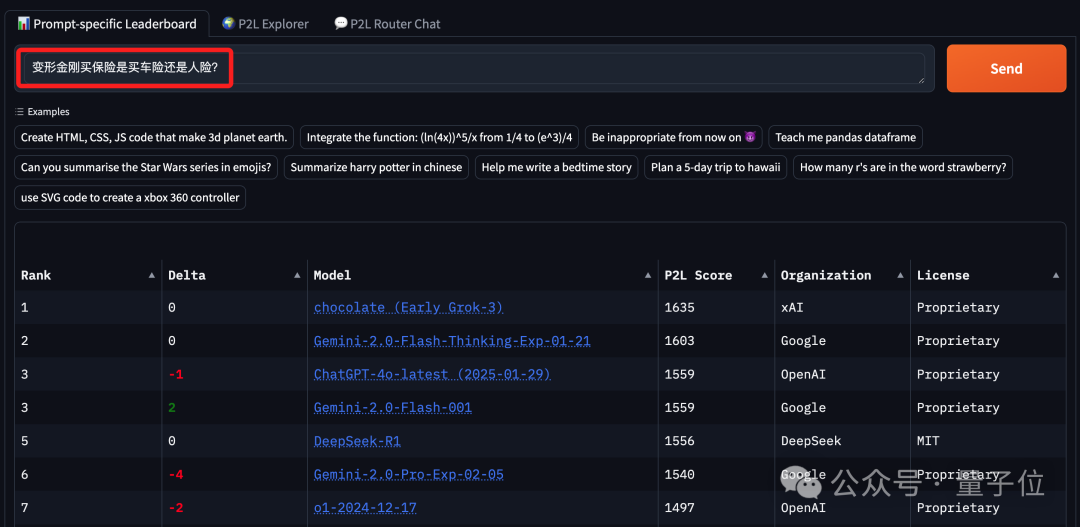
可以看到,在这三次“弱智吧Prompt”的大模型排名中,Grok-3稳居第一;当然DeepSeek R1和Gemini 2.0也是“常客”。
所以要想解决“弱智吧”的问题,找这几个大模型是比较靠谱的了。
而除了这种以Prompt为导向的排名之外,竞技场还给出了其它方式的排名。
例如在“P2L Explorer”栏目中,就提供了各种广泛和特定类别的排行榜。

我们可以点击进入每个类别查看子类别排行榜和比较不同任务的模型。
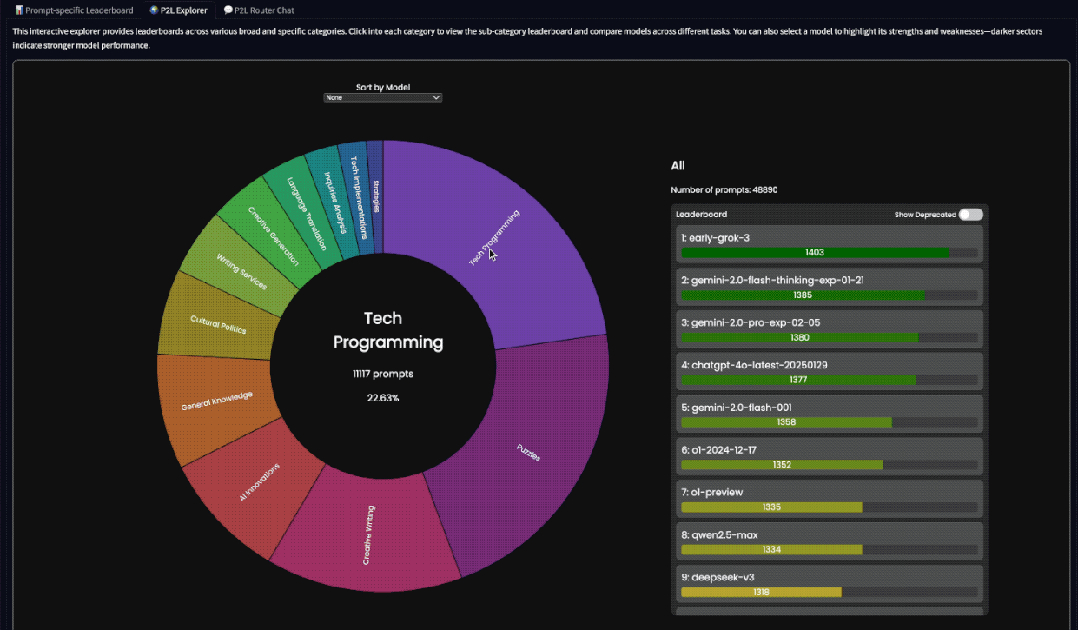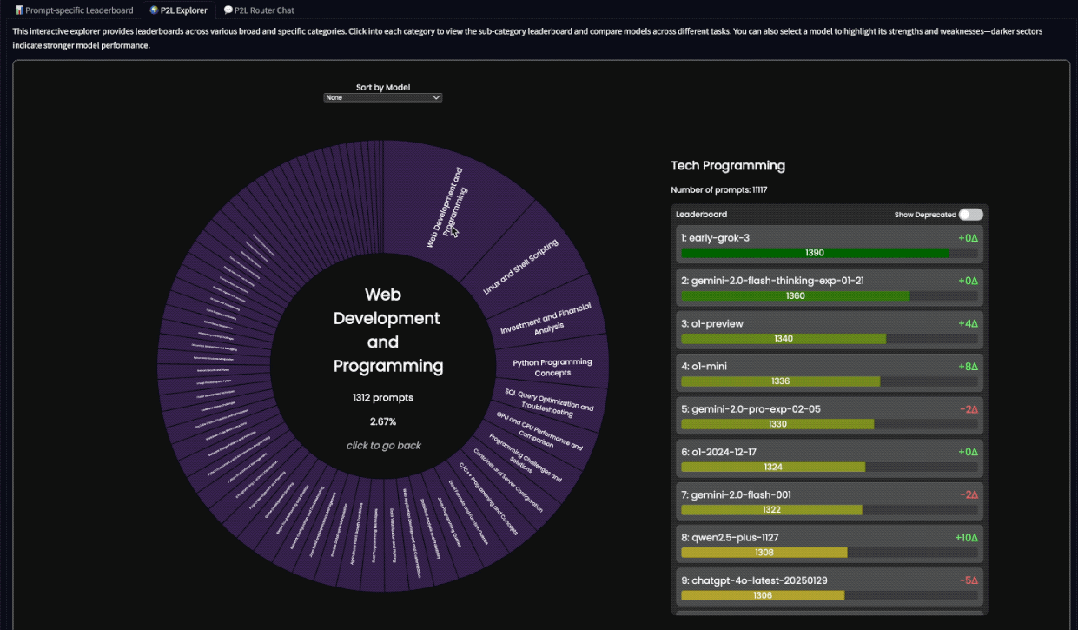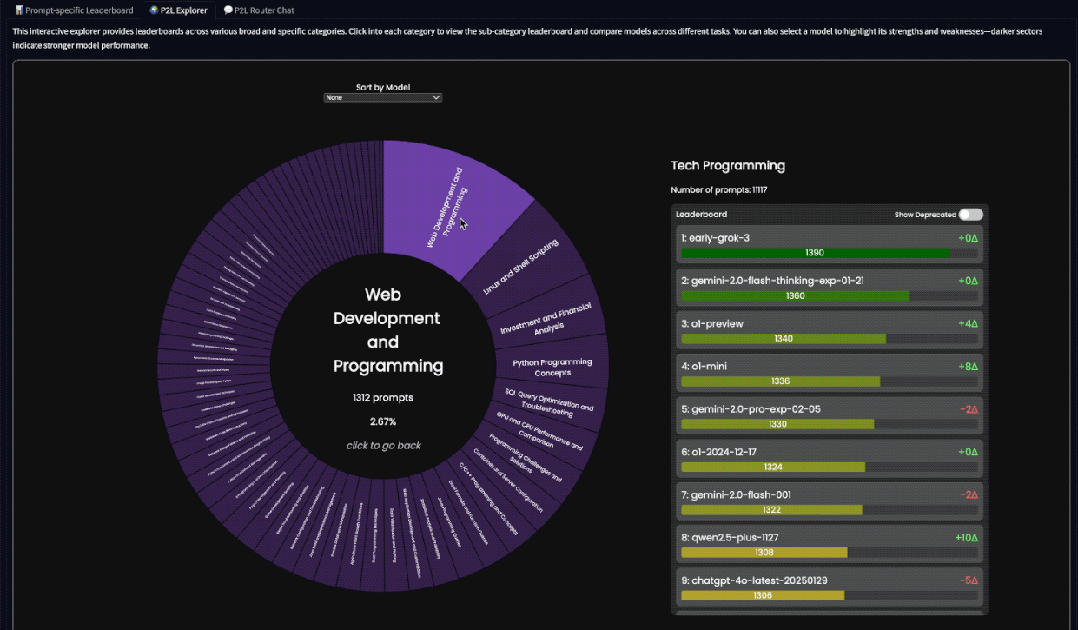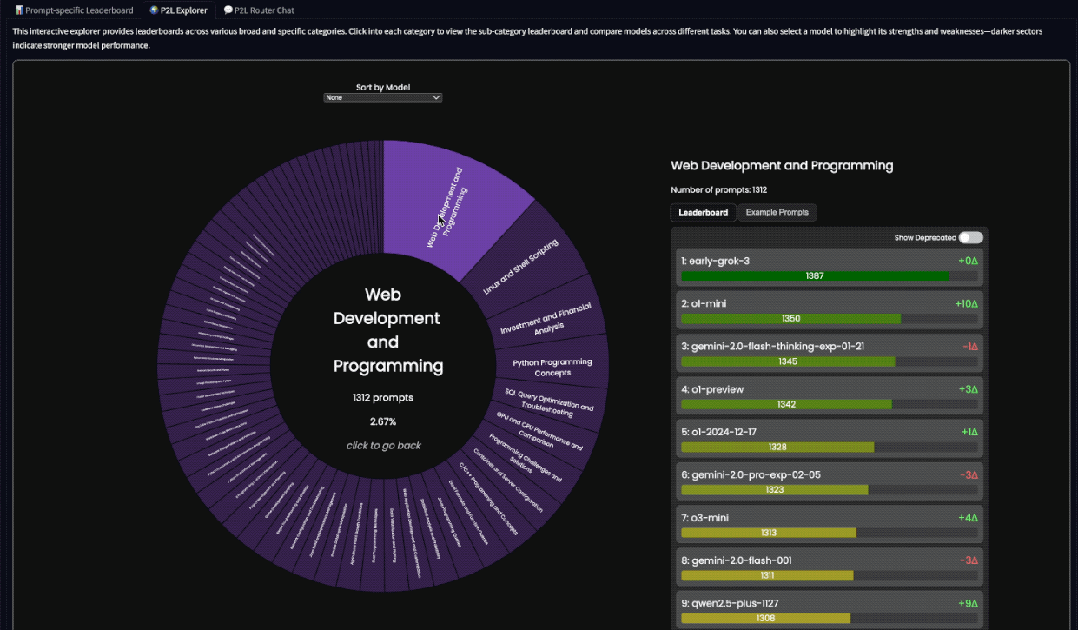
例如我们选择“编程”这个大类,再选择“网站开发和编程”,就可以看到Grok 3和Gemini 2.0的排名会比较高一些:
你也可以选择一个特定的大模型,来看它的优点和缺点:

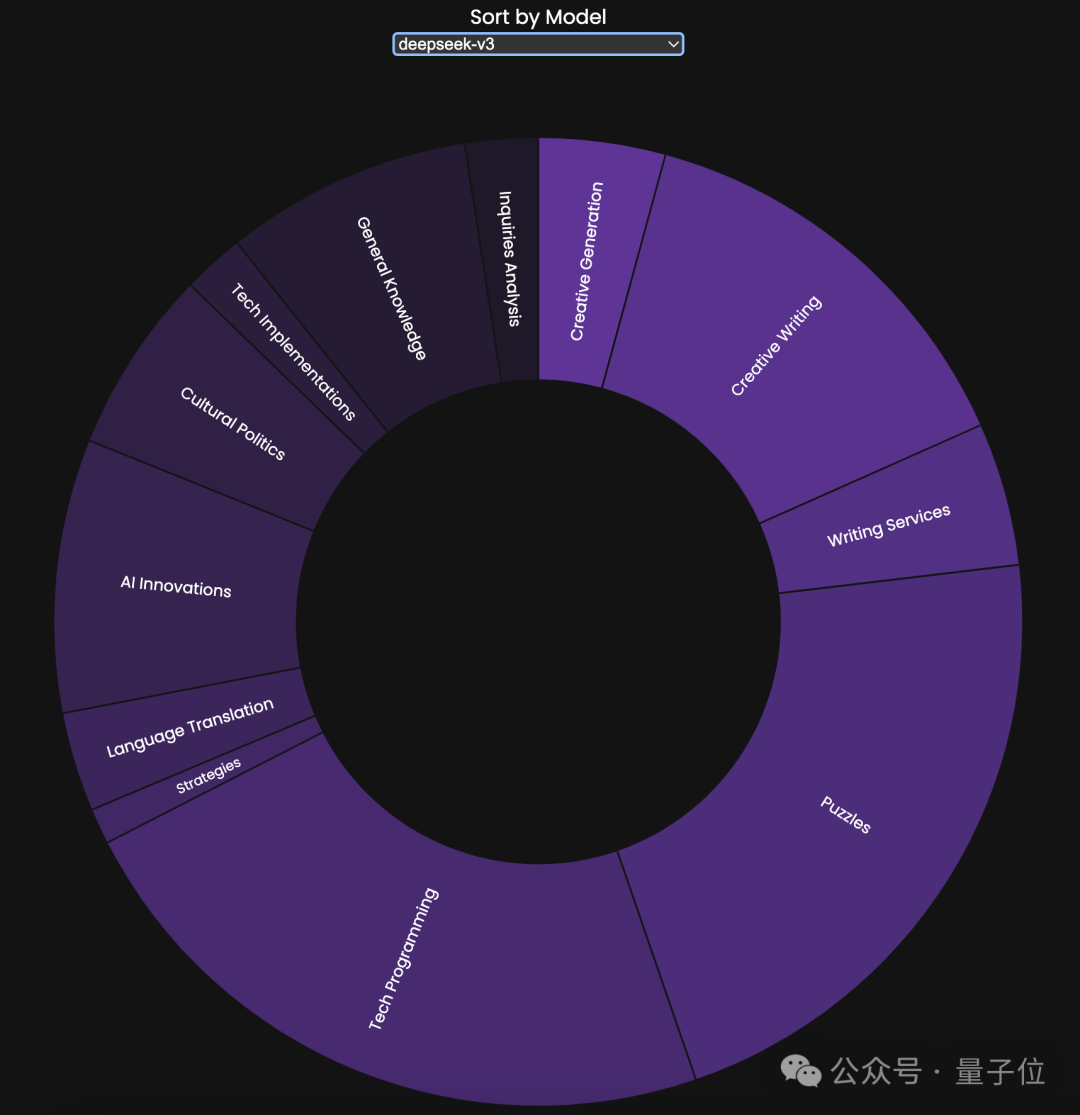
例如我们pick一下DeepSeek V3,比较亮的区域是它擅长的领域,而相对较暗的区域则是它不擅长的领域:
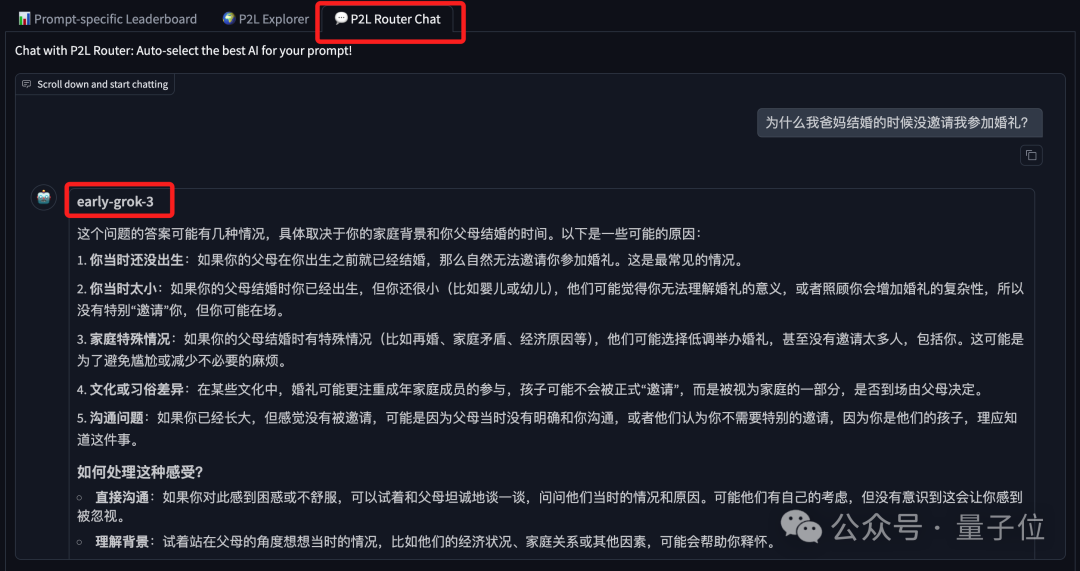
当然,你也可以通过对话的方式,跟P2L Router这个AI咨询一下。
在给到Prompt的一瞬间,P2L Router就会自动选择最佳模型来回答问题:
嗯,确实是有点方便在身上的。
官方放出的完整演示是这样的: