

01 用户行为分析
我曾经一度沉迷于用户行为分析,因为它背后对用户需求和行为的洞察是一件特别有趣的事。产品经理们常提及用户需求和价值,这固然重要,但它们最终都离不开定量研究的支撑。若一个用户需求脱离了发生频次、行为强度以及可替代性,那便是无根之木。
所以在某个周期内,我会把行为采集做得特别精细化。用户进入了A页面,然后点击了相关推荐,进而浏览B、C、D,我会尝试用source page的逻辑将其串联起来,并且辅以桑基图。
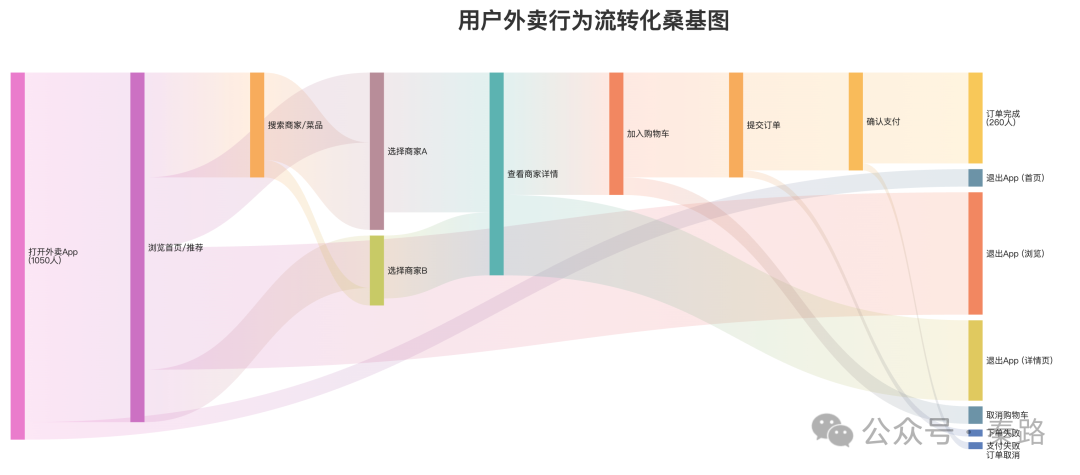
类似的场景数不胜数,这类User Journey的分析确实带来过收益,但也增加了数据采集和设计的负担。不止一次研发同学向我抱怨。
再后来,随着业务量的扩张,采集的数据进一步膨胀,包括历史版本的存量积累,导致计算和存储的开销成本达到一个夸张的地步。我们花费了特别多的时间治理。
在治理的过程中,发现了大量历史设计过,但实际使用为0的埋点。属于数据的屎山代码。光硬件成本就是数百万/月。那一刻你才会对数据采集的冗余度有充分了解。
回过头再看过往的分析,就会发现好的分析都是简练有美感的,而不是堆叠了多少图表。这时候你才会想明白,什么是「基于分析目标与假设设计数据」,什么是去芜存菁。
回到分析本身,新用户引导是一个绕不过的经典课题,每位产品经理都跃跃欲试。因为它具备比较大的策略迭代空间。最近看了一篇流传甚广的文章,说新用户引导毫无作用。
虽然我常开玩笑说,每年都会有一些新用户引导的尝试和迭代被翻来覆去地写入OKR,如有年度查重的逻辑,估计重复率挺高的。
挺能理解的,毕竟我自己就在新用户引导上做出过收益,还不止一次,笑。这不是说,新用户引导就是万能大招,可以和推荐pk效率,实际的判断,是要结合当下业务的逻辑。它有效,还是无效,是通过定量的行为数据来判断的。
以某个海外女性社区的产品为例,在MVP阶段,产品内的内容都是美妆、护肤、穿搭等。即使个性化推荐也上线,社区消费的表现仍旧一般。我做的策略是在冷启动的阶段,增加垂类引导,次留带来4~5%的绝对值收益。
具体的数据我忘了,当然记得我也不会说,但大致的分析逻辑如下:
1.海外女性的偏好比较多元,不同肤色的用户偏好不同的美妆;
2.即使同在护肤领域,用户在点击行为上也有离散性,有不同的功效偏好。干皮和油皮的点击天然就会隔离开;
3.护肤是连续的周期行为,会在多日内反复消费;
接下来我们细拆拆解行为,关注用户的搜索词,即新用户进入App是否马上发起搜索,以及具体搜索了什么。对新用户来说,如果首屏冷启动的内容不满足需求,那么她们很可能主动寻求。此时会关注冷启的内容和搜索query的相似度,用户实际想要的和我们提供的是否一致。
结论是不一致,进一步确认了初期的业务假设。同时搜索query的长尾词也足够多,说明需求是离散的。
美妆和护肤,护肤内的偏好又不一样,同一个偏好下又有品牌、功效的不同。说明用户的需求是足够精细的,而在短时间内,我们无法承接好这类需求。因此,通过分析报告,我们判断需要做新用户引导,快速聚拢用户的需求。
即使能承接好需求,我们产品还是缺一个独特的hook,因为在女性赛道,同类的产品和内容足够多了。我们的供给侧没有显著优势,当时在抽case的时候,发现用户有测评的习惯,包括创作端的发布数据也发现有不少用户会分享自己的肤质,具备讨论热度。
所以在强化引导的过程中,我们将业务逻辑封装成了护肤管理工具,女性用户可以通过一个简易的工具测评肤质,获得相关的标签可以直接优化推荐,例如干皮就不用推油皮的内容,提升用户对产品专业价值的感知。
最后feature上线,次留显著提升。当然,它还需要搭配其他策略,比如投流;再比如,通过皮肤管理工具,引导女性用户养成定期记录的习惯,提升粘性。
在一个垂直社区,初期少量的内容无法承接精细的推荐,新用户引导是有作用的。好比体育类目,喜欢足球的不一定喜欢篮球,喜欢梅西的不一定喜欢C罗。在这个层面做精细是没问题的。但是对一个大型内容平台而言,生态开始泛化,推荐效率提升,而兴趣选择因为数量太多了导致边际效益递减时,引导的效果就会弱化。
新用户引导是否有用,这是一个trade off的问题,选择的效率 vs 推荐的效率,它没有一个绝对的答案。但定量分析有。
上文探讨了用户行为分析的基本逻辑,其中用到的数据并不复杂,例如item_click、search_click等。相信你也能通过分析案例反推出参数结构,user_id、action_type、item_id,request_id。这些都是在枚举各类场景的埋点设计后,进而用于分析你所关注的内容的关键。
如何设计好你想要的数据。这是一个发散后再剪枝的基本功。
到这里为止,是曾经的草稿,我想写,但一直没有写完的内容。原本的内容挺丰富的,包含各类工具的炫技,现阶段我觉得不必要。因为工具和技巧,会结合下面分享的大模型心得。
02 LLM x 数据采集
通过上文的案例,你应该已清楚,采集数据是为了用以分析。数据从哪里来,数据到哪里去,如果「到哪里去」不清晰,那么哪里来就容易变得盲目。
我们这里从网络寻找一个产品设计原型图。
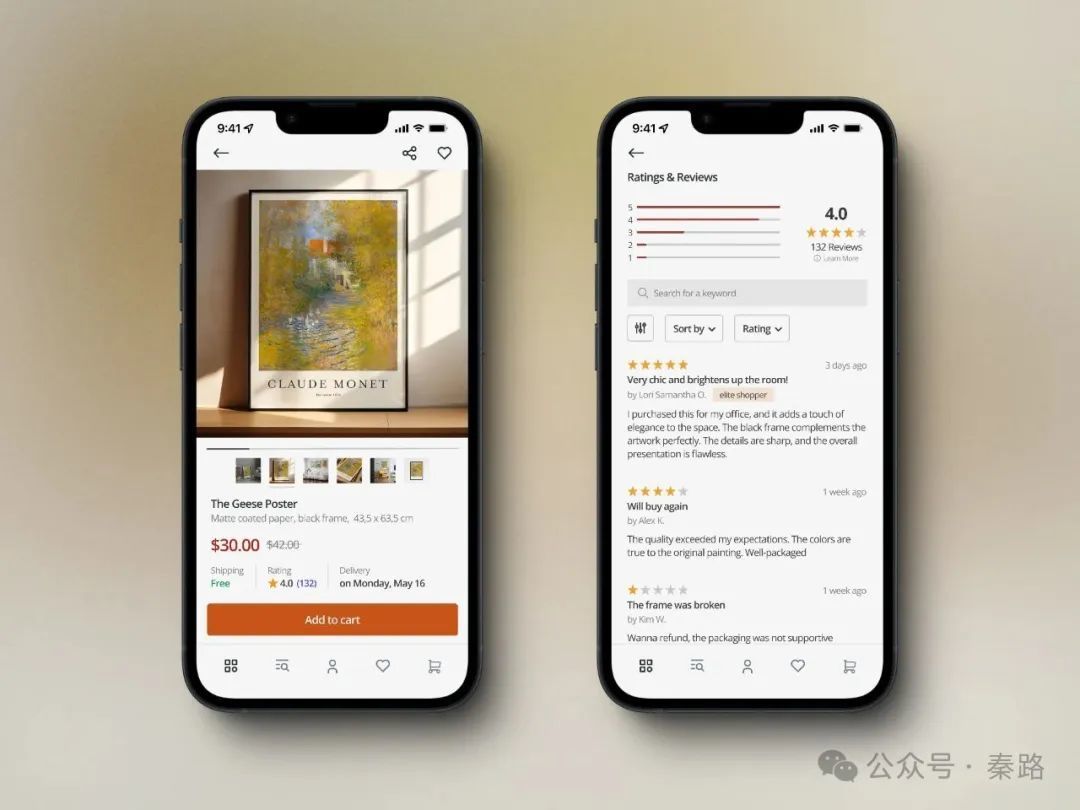
当你第一眼看到购买详情页,你会怎么思考它的埋点?
如果你还是一位数据分析的新人,不妨结合我上一篇的文章,学习和吸收后进行实践。接下来我们使用AI,我将尽量还原我的演示过程。
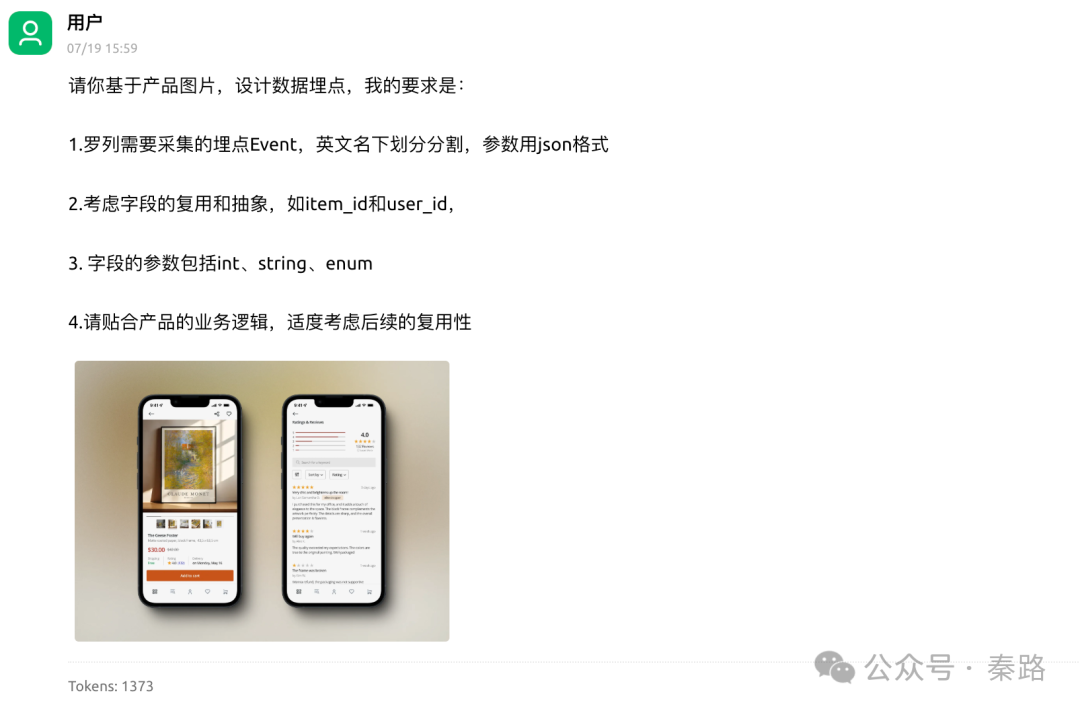
上述的Prompt,有分析经验的话稍加练习足够写出来,它是很具象化的数据分析/数据科学的know-how沉淀,我也没有用few-shot。接下来是LLM的输出:
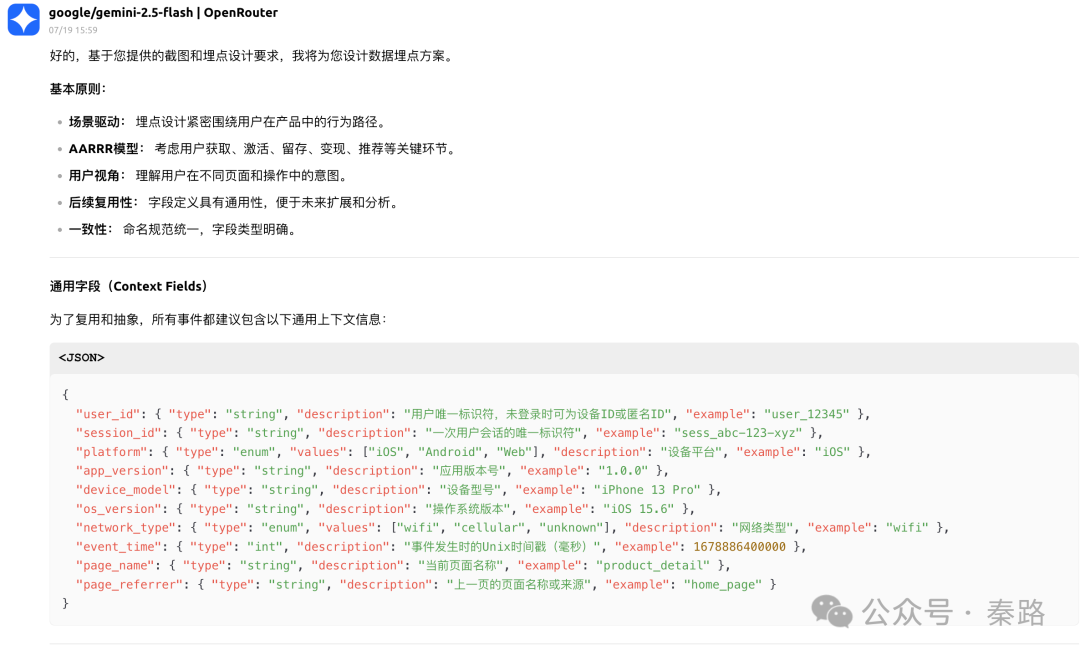

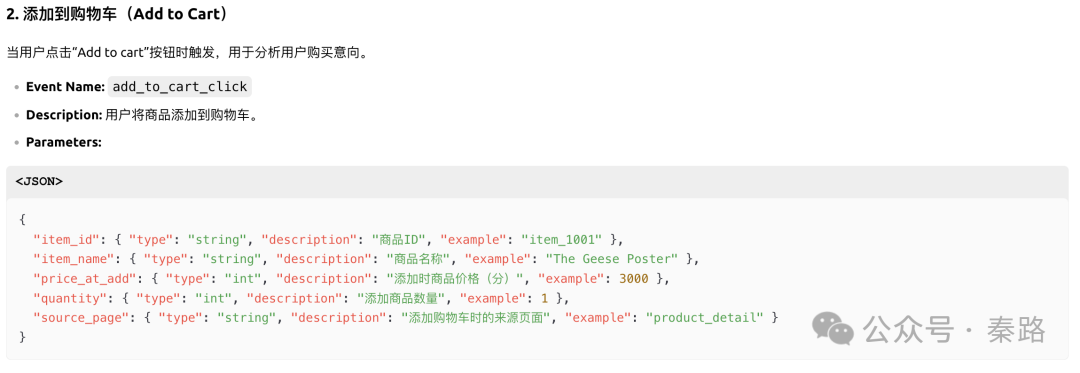



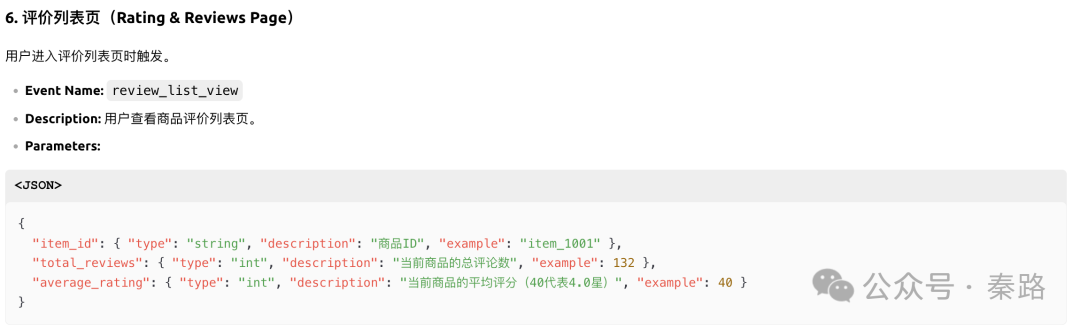
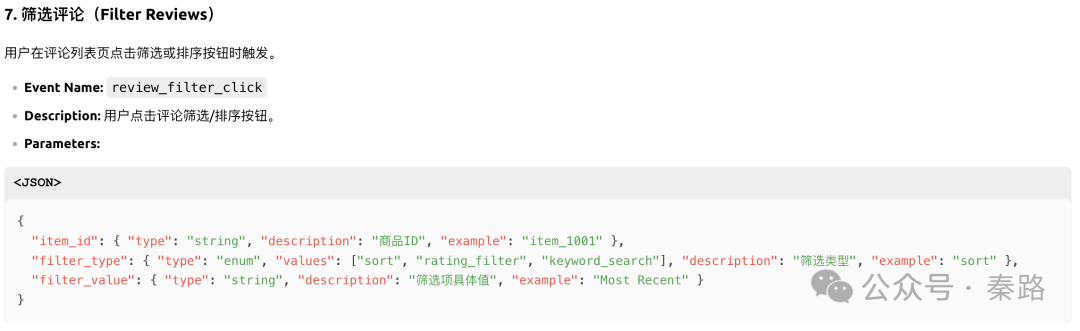


通过截图,我们能看到LLM已经能够覆盖基本的采集场景。虽然有不够优秀的地方,比如item_action_click过于通用,share和favorite最好不要合并(毕竟产品逻辑可能会发生变化)。
但当前的模型智能已经能读懂产品逻辑,并识别页面上所有的元素,包括容易被忽略的搜索评论输入框,点击评论(蓝色可点击状态)进入到评论详情页的交互等。
如果你熟悉RAG活知识库,那么埋点的字段规范和参数规范可以进一步精确约束。
以上的案例,我使用的是Gemini 2.5 Flash,还不是更聪明的Pro版本。
接下来,我们再用一段新的Prompt,让它基于产品设计原型图,先思考分析逻辑,然后再展开数据链路的工作:业务逻辑-分析框架-数据指标-数据埋点-数据建设,这本身就是一个清晰的ToDo List。

接下来是输出结果(埋点的篇幅我就略过了,没有特别大的差异,多出了一个评论停留时长的计算):


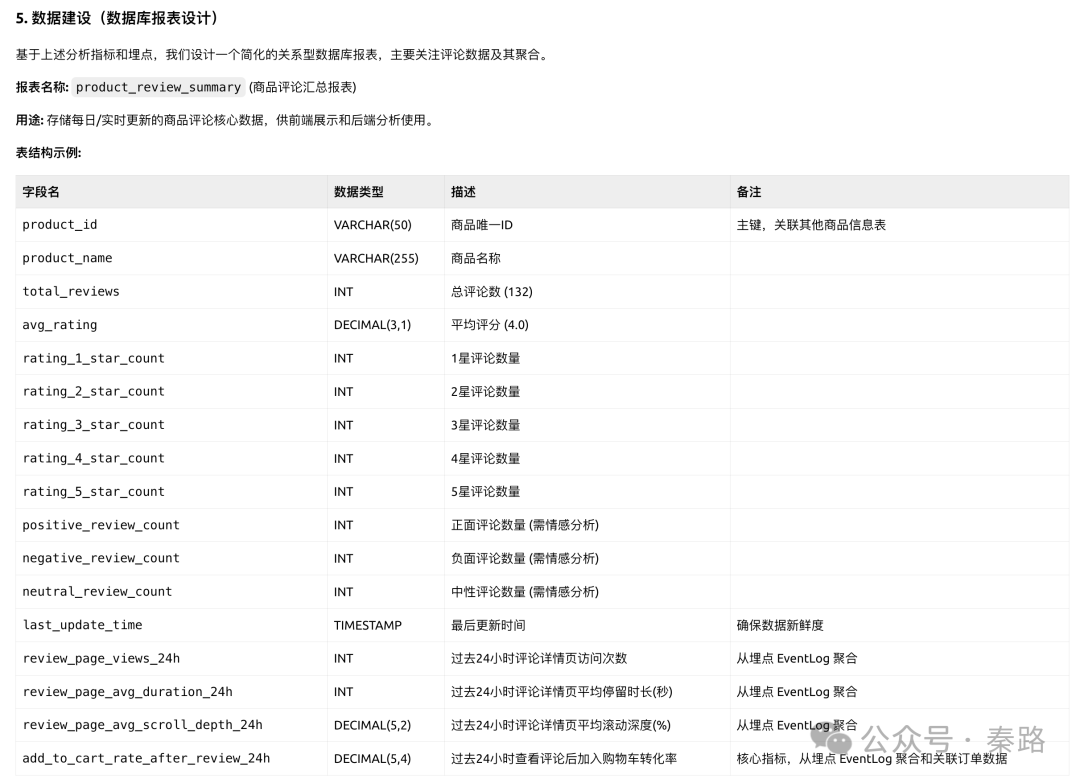
以上是分析目标、业务逻辑、量化因素、指标设计和建设的基本流程。这里暂时不对分析的好坏做评价,因为多轮对话可以修正逻辑。AI完成这类工作的效率已经足够快,原本半天的设计工作,可以大幅度压缩到分钟级完善。
本次演示,我没有用到复杂的Prompt/Tool,鉴于当前通用Agent如雨后春笋般冒出,我也不打算使用哪家来背书,仅仅是展示一下最基本的能力能够做到哪一步。
回想当年的课程内容花费了很多时间,现在有一半需要重构了,哈哈。
回到故事的第一个新用户引导案例,它是通过大量的行为数据推导得出的假设——女性用户在护肤场景需求是离散的,且初期的社区需要精细化的满足。现在的大模型或许难以完成这种梳理并提出优质假设,但如果你的假设足够 solid,那么后续的证明过程效率会提升几何倍呢?
我不想过于强调AI的优点或缺点,当它出现并且改变你的工作形式时,原有的初级-中级-高级-专家的学习范式就被改变了。即使埋点是重复性劳作,其背后的分析思路AI一时半会还学不会,但基础工作的生产力关系已经发生变化。
曾经在朋友圈看到一句话,在Flux和SD的文生图模型问世时,设计师朋友大感震撼,大家在设计峰会热烈讨论。然后实际情况是,100个设计师只有一半安装了ComfyUI,五分之一简单适用了ControlNet,最终只有两个人用Lora炼丹(然后kontext出来了)。
之前我写「七周」的时候,有人质疑,七周到底能不能学会?八年后的今天,纯粹使用工具的门槛已经大幅度降低,在human in the loop的模式下,你现在的学习需要几周?你又应该学习哪些?
产品PRD是最基本的业务单元,设想一下整个workflow的逻辑:输入PRD的文档(当前的上下文窗口足够理解),输出思路、指标、埋点、实验、ETL。每一个步骤可能只会做到80分,但是剩余的20分,又需要分析师花费多少时间呢?
这几年,我一直想着,是否将以前的公众号内容完善(不骗你)。既有新学习的心得和体会,也有完美主义的强迫症作祟。这下刚好,新的技术给了新的契机。
内容的更新,依旧是免费的分享。至于是否还需要教你Python、SQL和Excel和统计学?我认为是不必要的。
仔细想了想,如果你想锻炼量化/数据/分析的能力,那么往后可能是:
1.具备出色的设计数据workflow的能力,调度和统筹Agent,解决80%的标准场景。
2.AI Coding作为直接的生产力工具(我不会展开说第三方Agent,企业的数据是闭源的),解决20%的非标准化场景,基于Data的Coding会是主流。
3.提出优秀的业务逻辑和假设,证明和研究它。
作者 | 秦路 ; 编辑 | 荔枝