


Video4Edit团队 投稿
量子位 | 公众号 QbitAI
图像编辑缺训练数据怎么办?百度的研究人员决定直接从视频中取材。
传统的AI图像编辑方法依赖大量监督数据训练,数据成本高昂且难以覆盖多样化的编辑意图。百度的研究团队提出了一种全新的理论视角:将图像编辑视为退化的时间过程(Degenerate Temporal Process)。
Video4Edit通过利用视频预训练模型中的单帧演化先验(Single-Frame Evolution Prior),实现了从视频生成到图像编辑的知识迁移。实验结果表明,仅需主流编辑模型约1%的监督数据,即可达到与当前第一梯队模型相当的性能。
当前的「数据稀缺」与「权衡困境」
现有的基于扩散模型的图像编辑方法通常需要大规模的高质量三元组数据(指令-源图像-编辑后图像)进行训练。这种数据依赖不仅成本高昂,且难以覆盖多样化的用户编辑意图。
现有方法在结构保持(Structure Preservation)与纹理修改(Texture Modification)之间也存在根本性的权衡难题:过度强调结构保持会限制编辑的灵活性,而追求大幅度的语义修改又容易导致几何失真。
为此,Video4Edit项目团队提出:将图像编辑任务重新定义为视频生成的特殊退化形式。
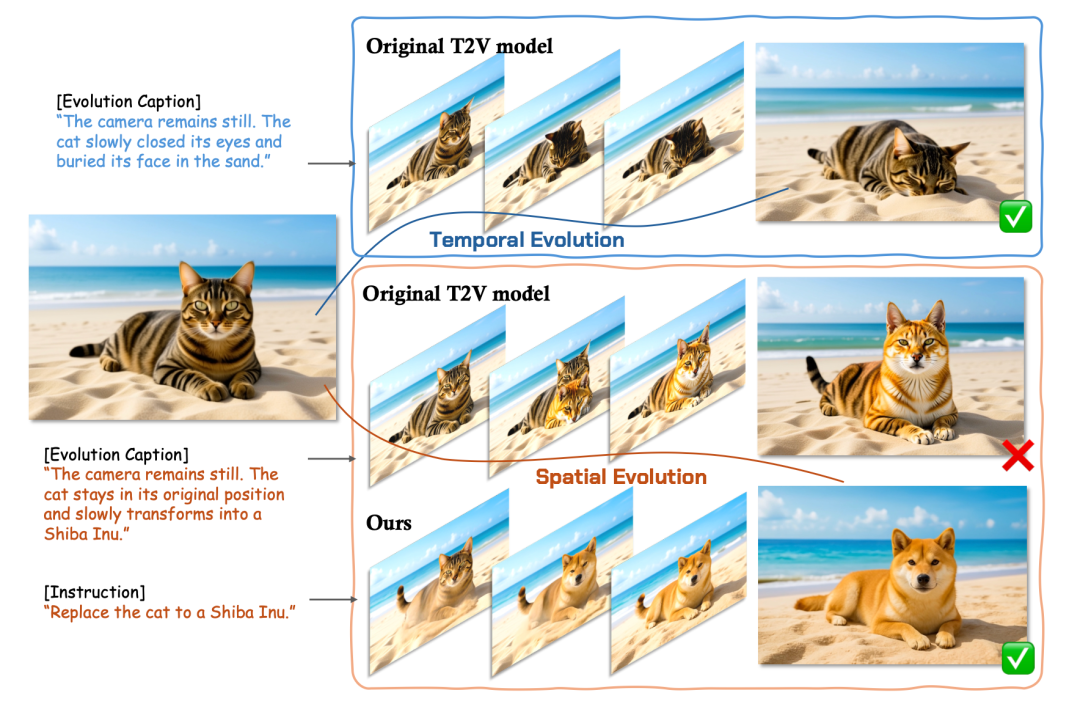
从时序建模的角度看,视频本质上是图像序列在时间维度上的演化。如果将源图像视为视频的第0帧,编辑后的图像视为第1帧,那么图像编辑任务可以自然地建模为一个2帧的极短视频生成过程。
按照这个思路,模型可以在视频中抽取的两帧图像上学习如何进行图像编辑,这样就可以快速大量获取无监督数据辅助进行模型训练。训练数据量的充足又在很大程度上得以改善结构保持与纹理修改间的权衡问题,让模型基于更充足的经验来处理图像,做到从心所欲而不逾矩。
从「灵光一现」到「工程实现」
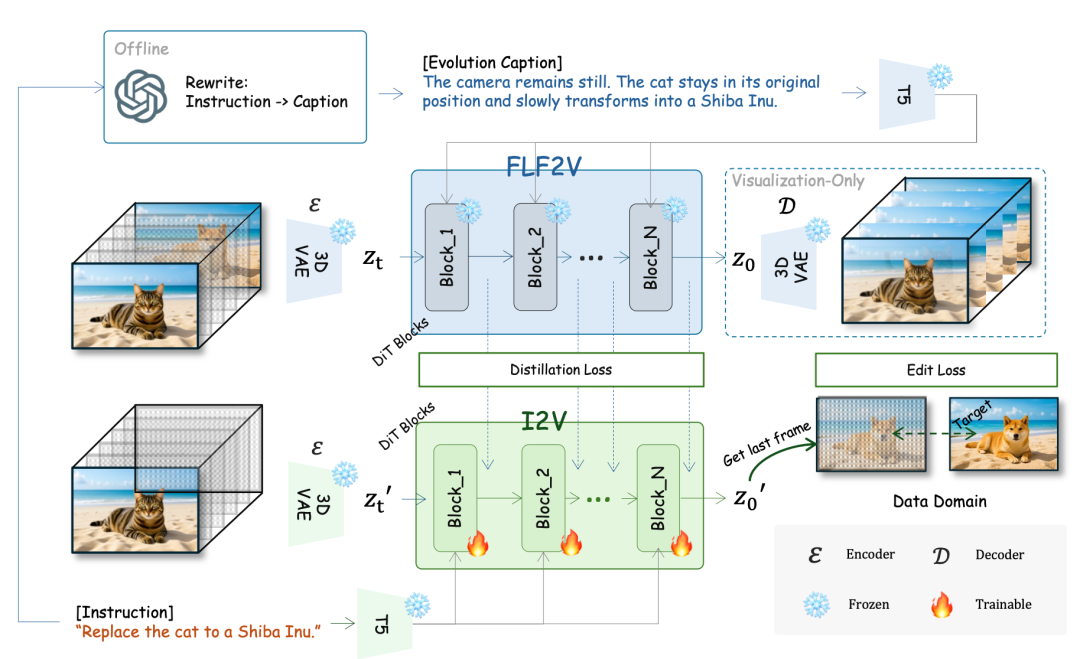
基于以上思路,团队利用视频预训练模型中蕴含的单帧演化先验(Single-Frame Evolution Prior)。视频生成模型在大量视频数据上预训练后,学习到了强大的时序一致性约束和帧间演化规律,这些先验知识天然地包含了结构保持与语义变化之间的平衡机制。
1. 时间退化建模
Video4Edit将图像编辑过程建模为从t=0(源图像)到t=1(编辑后图像)的时序演化。通过这种建模,原本需要显式学习的结构保持约束,转化为视频生成中成熟的时间注意力机制(Temporal Attention),该机制天然倾向于在相邻帧之间保持高频细节和几何结构。
2. 先验知识迁移
在潜在空间(Latent Space)中,视频模型学习到的zt→zt+1转移概率分布,可以通过文本指令进行条件化引导,从而将通用的时序演化能力重新导向为特定的编辑意图。
这种设计实现了参数的高效复用:模型主要学习编辑意图的对齐,而非从零学习图像生成能力。

3. 数据效率分析
从信息论角度看,引入视频先验极大地降低了假设空间的熵,提供了更强的有效泛化能力。
相比于从静态图像对中学习复杂的非线性映射,基于时序演化的微调具有更高的样本效率,这解释了为何仅需约1%的监督数据即可收敛。
效果展示
Video4Edit在多种图像编辑任务上进行了系统性评估,包括风格迁移(Style Transfer)、物体替换(Object Replacement)和属性修改(Attribute Modification)。
以下展示了不同编辑指令下的效果:
Instruction: Replace the text ‘TRAIN’ with ‘PLANE’.(将英文文本“训练”替换为“飞机”)


