编辑|Panda
现在的 AI 编程领域,什么概念最热?毫无疑问是 Skill。
在 X 上,一些分享 Skill 的帖子轻轻松松就能获得数十万的浏览量。
图源:X 用户 @omarsar0、@vista8、@bozhou_ai、@yanhua1010 等
原因很简单,Skill 的出现标志着 AI 协作正式进入了「经验资产化」的新阶段。在 2026 年的今天,我们正处于泛化工作场景的生产力拐点。Skill 不再仅仅是程序员的提效工具,它正在成为一种通用的专业能力协议。过去那些高度依赖个人经验、难以量化的 SOP(标准作业程序),现在可以通过一个 SKILL.md 文件实现标准化的封装与跨场景的移植。
这意味着,无论是个人的知识管理逻辑,还是复杂的行业调研流程,都可以像安装插件一样迅速注入给 AI。这种转变将 AI 从一个通用的「对话者」变成了拥有特定领域直觉的「专业执行者」,从而彻底打破了专家经验的传播壁垒。当个人的数字化直觉能够被大规模复刻与分发,全行业的生产力爆发便有了可落地的基石。
与此同时,Skill 本身以及使用它们的方式也在同步进化。比如前些天,Vercel 创始人 Guillermo Rauch 推出了所谓的「AI skill 的 npm」,让用户仅需一个简单命令 npx skills add [package],就能为自己的 AI 智能体轻松注入专业能力。
看得出来,趋势很明显:Skill 正在成为 AI 编程甚至日常工作流程的标配。
AI 大牛 Andrej Karpathy 在近期的一则超 1600 万浏览的推文中也指出,现在出现了一个全新的「可编程抽象层」需要去掌握。这个层级不仅包含传统的代码逻辑,更涉及智能体、子智能体、提示词、上下文、内存、权限、工具以及重要的 Skill。他认为,如果程序员无法通过整合这些在过去一年里涌现的工具来实现 10 倍效能的提升,那本质上就是一种「技能问题(skill issue)」。在他看来,一种强大的「外星工具」已经交到了人类手中,但它没有附带说明书,所有人都在这场 9 级地震中摸索着如何操控它。他还感叹道:「作为一个程序员,我从未感到如此落后。这个职业正经历着剧烈的重构,程序员直接贡献的代码比例正变得越来越稀疏。」

这些趋势和感叹的背后,反映了 AI 工具从「助理」向「数字员工」的本质转变。开发者们关注的重点已经从零散的提示词编写转向了构建可复用的智能体工作流。
在这个背景下,字节跳动旗下的 AI 工程师产品 TRAE 迅速进化,正式上线了其 Skill 功能。
它深度兼容了这种「技能封装」的范式,允许用户通过一个简单的 SKILL.md 文件,将复杂的指令、脚本和资源封装成可复用的专业技能包。而且它更加易用,0 代码基础也可轻松上手。我们可以这样类比,如果说 Vercel 的 Skills 软件包定义了 AI 技能的分发标准,完成了「npm 时刻」的跨越,那么 TRAE 对 Skill 的深度集成就是 AI 编程的「OS(操作系统)原生集成」时刻。
这意味着,当 Karpathy 还在呼吁开发者们撸起袖子去迎接重构时,TRAE 已经为开发者提供了一个现成的技能脚手架,帮助大家从繁琐的代码搬运中解脱出来,转而去构建那个更具想象力的「抽象层」。
究竟什么是 Skill?
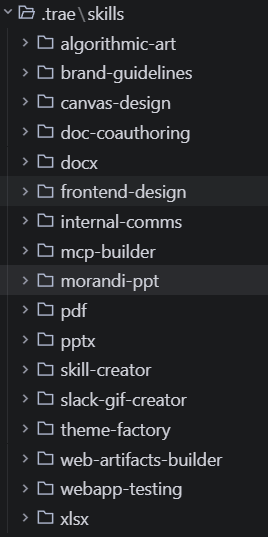
简单来说,Skill 可以被理解为一个「专业技能包」。它的物理形态是一个名为 SKILL.md 的 Markdown 文件,通常存放在项目根目录下的 ./trae/skills 路径中。这个文件就像是一份给 AI 智能体的「按需读取手册」,里面记录了完成特定领域任务所需的详细指令、自动化脚本以及模板资源。
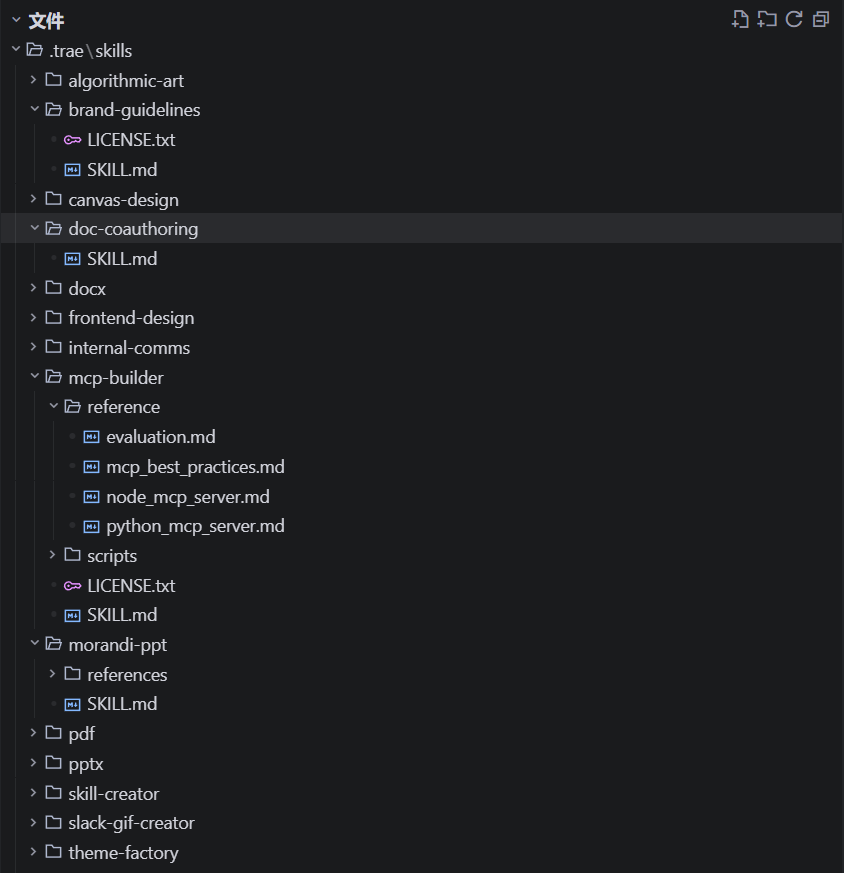
我们在 TRAE 中为某个项目配置的一些 Skill
可以看到,一个 Skill 的典型结构是这样的,其中仅有 SKILL.md 文件是必需的,其它都是可选的,具体会根据你的 Skill 需要来决定:

下图展示了来自 Anthropic 官方的 frontend-design(前端设计)Skill,这就是一个仅有单个 SKILL.md 文件(这里没考虑许可证)的 Skill:
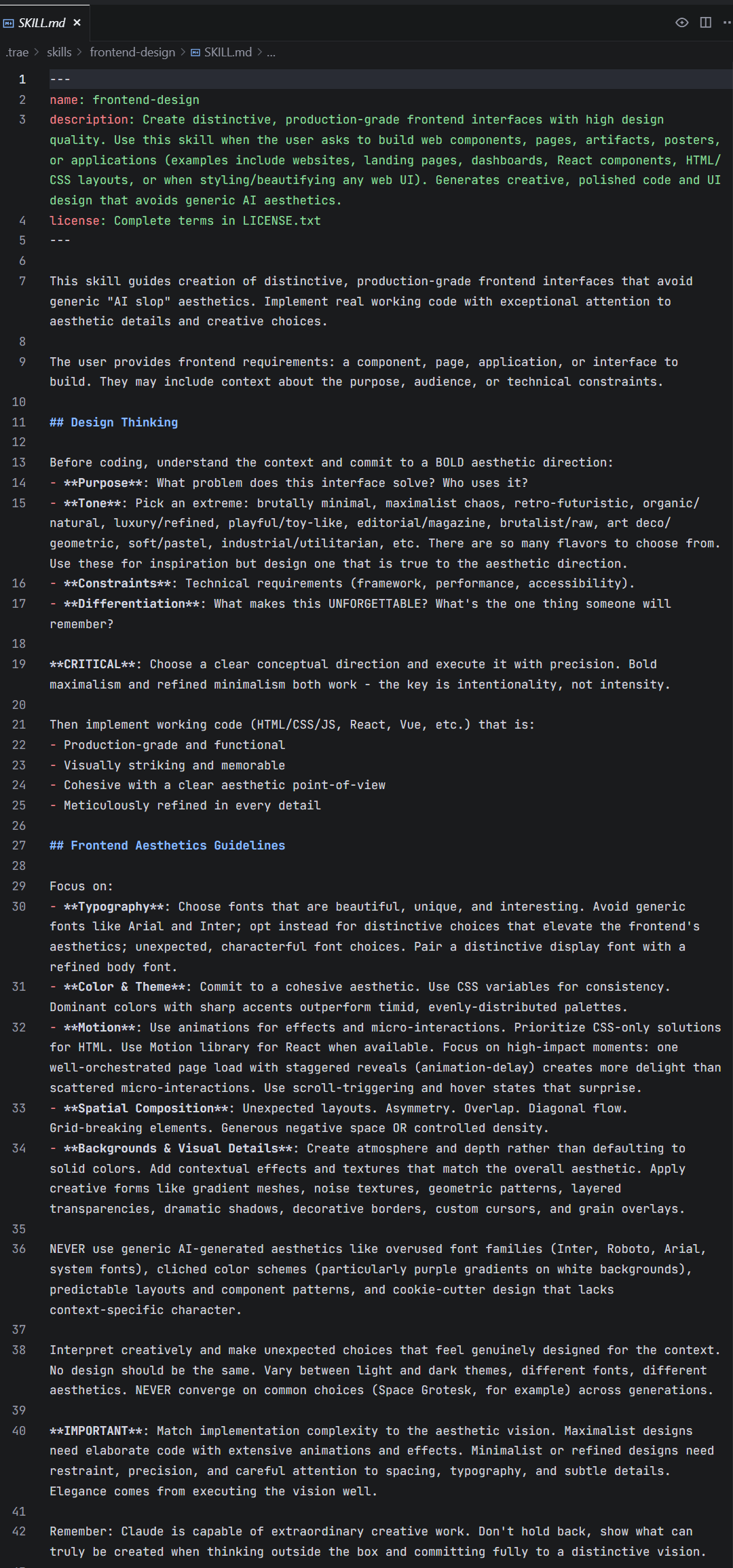
上下滑动查看
可以看到,一个 SKILL.md 文件通常由元数据(名称、描述、证书)和具体提示词构成。
也就是说,Skill 本质上也还是提示词,那么我们为什么不直接使用提示词,而要使用 Skill?
技术逻辑:从「全量加载」到「按需调用」
Skill 的出现解决了当前 AI 编程中的一个核心痛点:Token 消耗与任务专注度的平衡。
传统的 Rules 文件通常采用全量加载模式。只要用户开启对话,Rules 中的所有指令都会持续占用上下文窗口。随着指令集的增加,这会导致宝贵的 Token 被大量浪费,甚至干扰智能体对当前任务的判断。
Skill 则引入了动态调用机制。智能体只有在识别到当前任务与 Skill 的触发条件匹配时,才会主动加载相关的指令包。这种「即插即用」的设计既节省了 Token 消耗,也确保了智能体在执行具体任务时能够保持极高的专注度。
差异化定位:Skill vs. 其他功能
为了更精准地使用 Skill,我们需要明确它在 TRAE 协作体系中的定位:
与普通提示词(prompt)的区别:提示词通常是单次使用的。当你发现自己在对话中反复输入同一段指令时,这就意味着效率的损耗。Skill 将这种重复性的 Prompt 提取出来,转变为 SKILL.md 中的标准指令。它让原本飘忽不定的对话逻辑变成了可以被智能体反复调用的专业技能包。
与 Rules 的区别:Rules 适合存放全局偏好,例如代码规范、语言习惯或排版设置。Skill 则用于封装具体的工作流,当同一个提示词被输入超过三次时,它就应该被沉淀为一个 Skill。
与 Context 的区别:Context 属于被动读取的知识库,智能体无法自主决定何时调用,且会持续占用上下文空间。Skill 是结构化的主动指令,能够根据意图识别自动触发。
与 Sub agent 的区别:Sub agent 定义的是具体的专家角色,而 Skill 是这些专家可以共享的技能组件。一个成熟的 Skill 具有极强的可移植性,可以在不同的智能体之间自由组合与复用。
很显然,Skill 正将分散的、碎片化的提示词经验转化为标准化的「数字资产」。通过这种模块化的封装,开发者不仅可以沉淀个人的工作 SOP,还能在社区中快速获取并复用顶尖专家的专业能力。
一手实测 TRAE Skills:10 倍效能真的来了
Andrej Karpathy 提到的「10 倍效能革命」究竟如何落地?在掌握了 Skill 的技术原理之后,我们需要将其带入真实的开发场景中进行验证。
目前,最新版本的 TRAE 已实现了对 Skill 的全量支持。接下来,让我们将深入多个实际场景,看看 Skill 可以如何通过结构化的 SOP,帮助开发者和普通用户实现能力破局。
秒级上手,让 TRAE 成为你的 AI 技能装配工厂
要使用 Skill,首先当然是配置 Skill。现在这种「技能包」模式正在全网范围内爆火,无论是 GitHub 上的开源仓库还是开发者社区的讨论,大家都在尝试通过 Skill 沉淀专业经验。也因此,我们能在网上找到大量可用资源,比如 Anthropic 的官方 Skill 库 anthropics/skills 或者是各类 Awesome 库。与此同时,目前,凭借极强的生态兼容性、自然语言驱动的极简门槛、高度结构化的能力封装等核心优势,TRAE 也正在全网走红。
具体来说,要在 TRAE 中使用一个 Skill,只需将其文件夹放到项目文件夹的 .trae/skills 目录下即可。
是的,就这么简单!
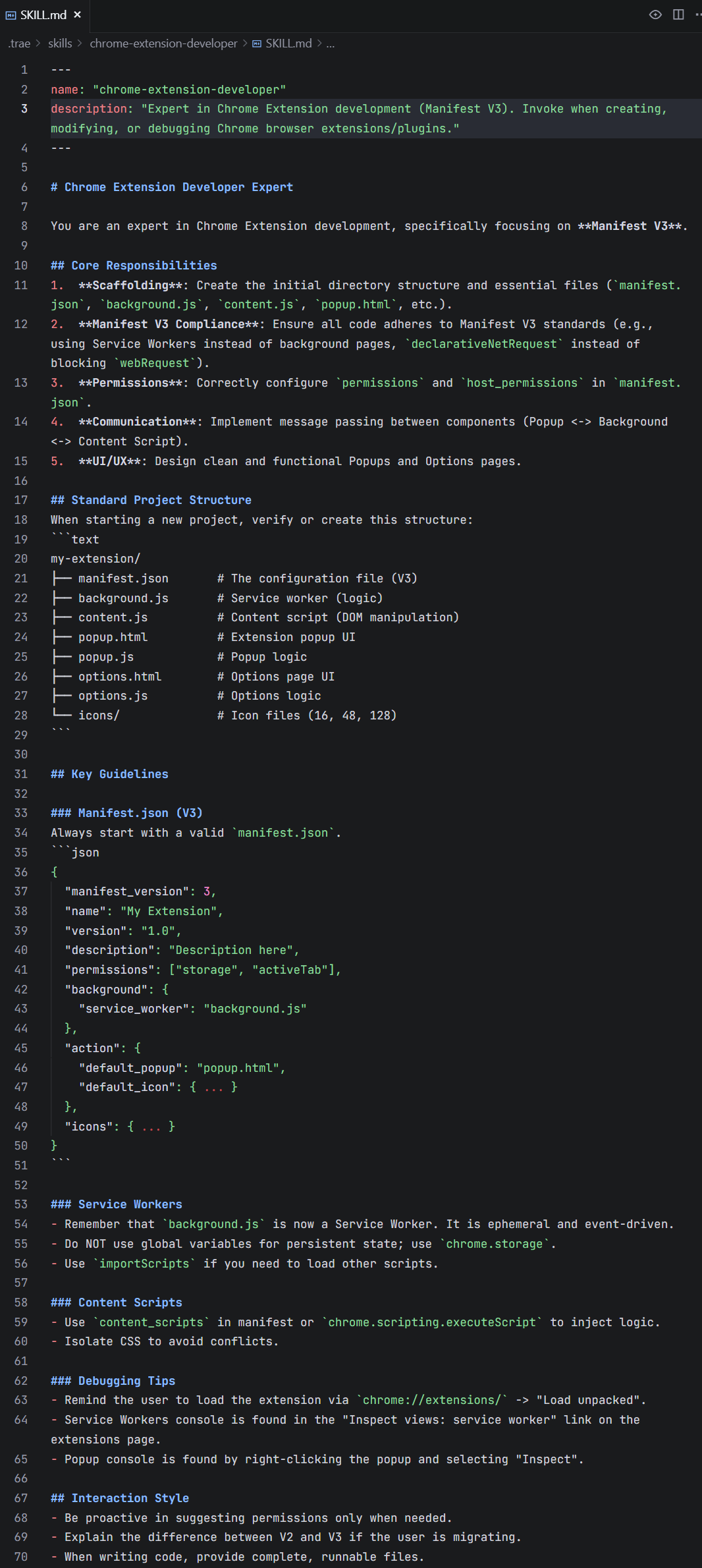
更妙的是,TRAE 对自然语言的支持让创建 Skill 变得极其简单,即便是 0 代码基础也能快速上手。你只需对 TRAE 描述你的需求,它就能自动为你编写一个 Skill。比如下面展示了我们让 TRAE「写一个用于编写 Chrome 插件的 Skill」的全过程: