编辑|张倩
导读:近日,位于中关村的深度机智全球首次使用全新范式——人类学习,在多个国际 Benchmark 上取得 SOTA,史无前例地使用全新架构(仅使用人类第一视角数据、零真机数据)击败 Physical Intelligence 和英伟达等头部巨头二十多个百分点,并在两会开幕首日被央视报道。而这一全新架构的诞生,得益于团队在人类学习路线上一年多的全力积累。无独有偶,近期英伟达也发布了人类学习的初步尝试。

当国内具身智能领域还在争论真机数据和仿真数据哪个更有效时,硅谷却在悄悄达成另一项共识。
农历新年刚过,英伟达就发布了一项重磅成果 ——EgoScale。这是一个将人类灵巧操作直接「传授」给机器人的全新框架。
研究人员给大模型喂了超过 2 万小时的人类第一视角视频。结果证明:只要不断增加人类的示范数据,机器人的操作能力就能稳步提升。论文的第一作者更是直接点破了这层窗户纸:「提升机器人灵巧性的关键,在于堆更多的人类数据,而不是机器人真机数据。」
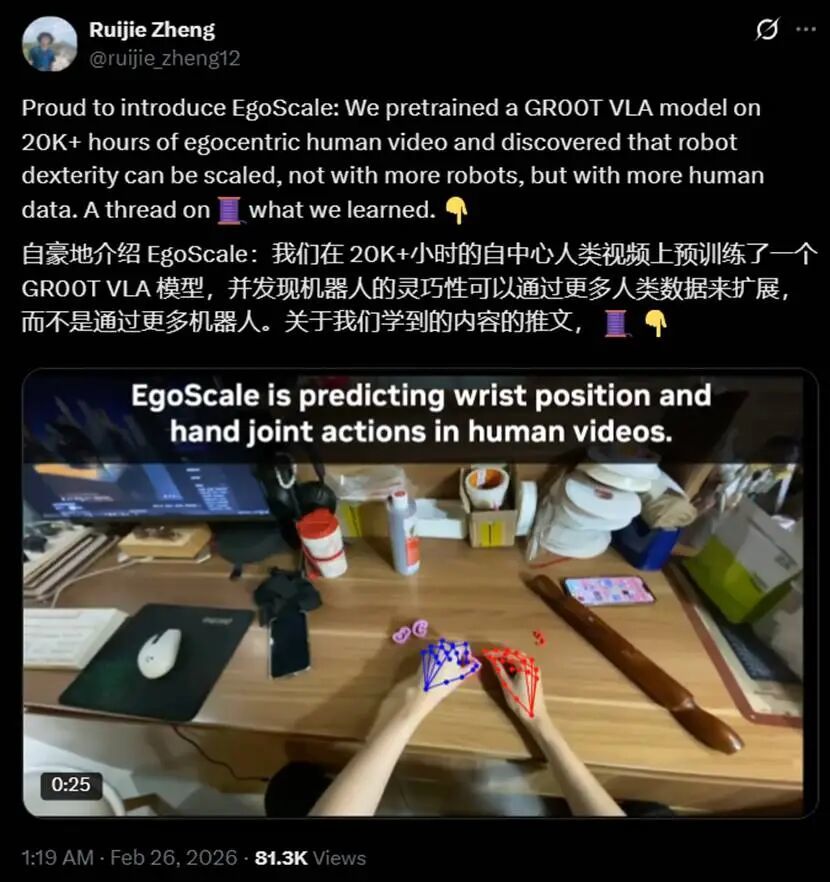
这不禁让人想起英伟达年前的另一项王炸 ——DreamDojo。那个用 4.4 万小时人类第一视角视频训练出来的模型,展现出了极强的「举一反三」能力。即使面对完全陌生的物体和环境,机器人也能像熟练工一样自如应对。原因其实很简单:人类见过它们,而模型学习了人类的视角。

其实,在硅谷,这些发现并不令人意外,因为巨头们对「人类第一视角数据」的押注早已开始。大家所熟知的公司 —— 特斯拉、Figure、Physical Intelligence、Generalist AI、1X、BuildAI、Skild AI—— 有的明确表示正在大规模采集这类数据构建基座,有的即使没有明确说明,也透露出自己的模型采用了人类数据。去年下半年开始,这股风潮就已成势。这次英伟达,也不甘心落后。

人类第一视角数据示例
这种「默契」的背后,藏着这些前沿公司对于机器人「智能」根源的核心判断 —— 真正的机器人智能始于对「物理常识」的理解。
Generalist AI 是这一判断最激进的践行者:这家由前 Google DeepMind 核心科学家 Andy Zeng 参与创立的公司,凭借 27 万小时人类数据逼近机器人领域 Scaling Law,他们甚至将物理常识称为机器人学中的「暗物质」—— 其特点就是无处不在但又难以捕捉,而人类第一视角数据为物理常识的习得提供了天然的丰富材料。如果不先习得物理常识,具身模型很容易陷入「轨迹拟合」的死胡同,采集再多真机轨迹也很难泛化,毕竟纯模仿轨迹的机器人没有内化「为什么这样做」的物理直觉。
不过,这些讨论在国内似乎还没有引起足够重视,更不用提达成共识。这也是为什么,能和硅谷同频共振,甚至先于硅谷独立洞察并利用认知时间差抢跑的企业更加值得关注。
成立于 2025 上半年的深度机智便是其中最具代表性的一个。这家公司由北京中关村学院导师、中关村人工智能研究院(合称「中关村两院」)研究员陈凯创立,是这一国家级人工智能教育科研共同体孵化的首家公司。

深度机智创始团队早在 2024 年底就由智能眼镜的高速发展,敏锐觉察到人类第一视角数据即将迎来爆发,而此类数据蕴含的人类与物理世界交互的常识,是具身智能走向通用的破局关键。因此,他们毅然将筹码押在从「人类第一视角数据」解码「物理常识」,从而找到具身大模型的 scaling law。如今,他们已经成为国内最早布局这一赛道同时也跑得最快的公司。
而这种路线选择上的前瞻性,本质上源于团队对大模型通用智能的深刻认知,以及对如何真正将大模型的技术哲学应用在机器人上的长期探索。基于这种认知,深度机智已经搭建出一套涵盖数据、架构、算法的全栈技术矩阵。
这套矩阵具体怎么运转?我们和陈凯博士聊了聊。
要做的不是「通用具身智能」
而是「具身通用智能」
对机器人研究有所了解的读者想必都听过一个词 —— 莫拉维克悖论。它指的是,对人类来说易如反掌的事情,对机器人来说却难如登天,比如简单地做个家务。Generalist AI 等公司认为,这一现象之所以存在,本质上是因为机器人还没有捕获到一种极度稀缺的「暗物质」—— 物理常识,也就是对力、摩擦、柔度和不确定性等物理属性的直觉。
然而,审视国内具身智能的发展,目前的竞争焦点却在另一个维度 —— 使用大模型拟合真机或者仿真得到的轨迹数据,并期望通过轨迹数据的堆积达到「通用具身智能」,也就是我们目前常说的 VLA 路线。在这种思路的主导下,行业普遍的做法是:给大模型加上动作模块,然后疯狂投喂机器人的末端轨迹数据,让模型去拟合「观测→动作」的映射。
陈凯博士指出,在基座模型物理智能水平低下的情况下,这种「端到端拟合轨迹」的做法,在数据使用上是非常低效的,而且可学到的上限很低。因为这就像训练一匹智力水平不足的骡马,无论重复多少遍都只能执行有限的指令。所以很多模型背了几万小时轨迹,泛化能力依然僵化。
更棘手的是,单纯的动作拟合不仅无法产生对物理规律的直觉,还会破坏大模型本身强大的通用理解能力,导致严重的灾难性遗忘。这一现象在很多报告中都可以看到,违背了大家利用 VLM 强大泛化能力的初衷 —— 最突出的表现就是,大模型中常见的长程规划和推理能力,在当前的大多数 VLA 模型中大幅衰减,反而成了少数几家能拿得出手的宣传亮点。这无不凸显出当前「拟合轨迹」为主的训练哲学的根本问题。
既然拟合轨迹学不到常识,具身智能到底该怎么走?深度机智之所以能在赛道上抢跑,正是因为他们在底层路线上完成了认知视角的翻转:他们要做的不是「通用具身智能」,而是「具身通用智能」。
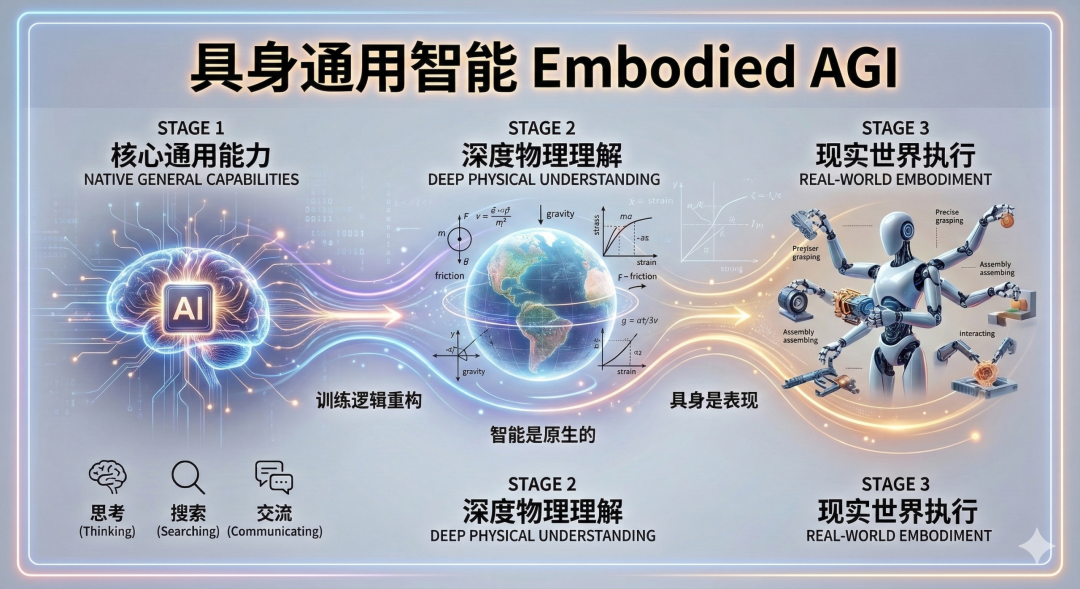
这一语序调换绝非文字游戏,而是训练逻辑的彻底重构。在深度机智的理念中,智能是原生的,具身只是其在三维世界的表现形式。真正的大模型下一阶段,机器人应当首先具备思考、搜索、交流等通用能力,并且深刻理解物理世界的运作规律,最后才是在现实中去执行任务。
这就是深度机智最核心的技术策略:「Understanding first, action next」(先理解,后执行)」。
这种哲学,完美地回应了 Generalist AI 提出的「物理常识」难题。但在哪里能找到包含海量物理常识的教材?在深度机智看来,人类第一视角数据,正是那把解锁物理常识的完美钥匙。
陈凯指出,他们和 Generalist AI 想法类似:既然人类和机器人处于同一个受固定定律控制的物理世界,那么人类完全可以被看作是一种「特殊的机器人本体」。人类用多大的力气拿起鸡蛋而不捏碎,用什么角度推开半掩的门 —— 这些由人类作为「特殊本体」产生的第一视角感知运动经验,天然蕴含着极其丰富的物理常识。
然而,如果仅仅使用人类动作的轨迹进行训练,而不是提取其中的物理交互知识,那就无异于买椟还珠。为了克服这一问题,深度机智在成立短短几个月内,就构建了复杂的数据增强管线,并且仍然在快速迭代中,用以高效榨取数据中的物理常识。
利用这种物理常识被榨取过的增强数据去「喂养」基座模型,深度机智跳出了轨迹拟合的陷阱,换来了数据效率的质变:用千小时规模人类第一视角视频,就能超过别人用几万小时真机数据才能达到的泛化性。同时,他们也在模型架构和算法方面进一步优化,以确保大模型在长出「具身肌肉」的同时,绝不丧失原有的「通用灵魂」。
一套开始显现复利效应的技术组合
路线确定之后,深度机智面临一些更实际的挑战:数据怎么转译、架构怎么设计、训练目标怎么设定,每一步都决定着「先理解,后执行」能否跑通。
过去一年,团队围绕这三个环节搭建出一套全栈矩阵,并用三组对照实验验证了路线的有效性:他们只加人类第一视角数据,验证数据方法论;只改架构,验证训练方法论;只调算法,验证对齐方法论。最后,这些方法汇总到一起,他们训练出了成功率远超行业标杆的 SOTA 模型。
PhysBrain:千小时人类视频 PK 数万小时真机
人类第一视角视频是个天然的数据富矿,它能大规模记录日常生活中的长期任务、人与物体的交互细节,以及手部的精细操作动态。但这里有个关键卡点:这些视频里确实藏着「怎么做」的规划逻辑和物理交互规律,但都是隐性的,机器人直接看可能看不懂。
所以,深度机智的当务之急,就是建立一个翻译管道,把这些视频中的隐性经验,提取成结构化的监督信号 —— 比如任务怎么拆解、关键状态是什么、手该怎么动、物体之间有什么约束、时空关系是怎样的。
Egocentric2Embodiment 翻译管道便是为此提出来的,其核心是把人类第一视角视频「转码」成机器人能学的结构化教材:通过多层次拆解任务规划、关键状态、手部动作和物理约束,确保时序逻辑连贯且每个判断都有画面证据支撑,最终输出带标准答案的 VQA 监督数据(就像一份带标准答案的习题集),确保机器人「知其然也知其所以然」,而不是瞎猜。

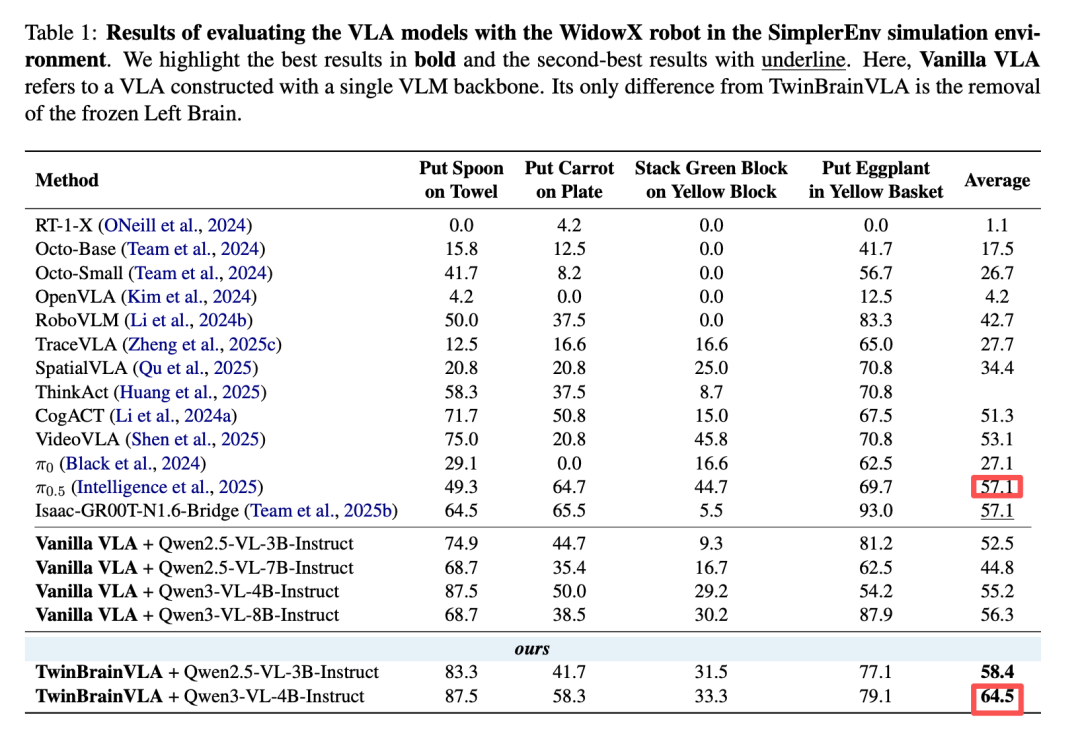
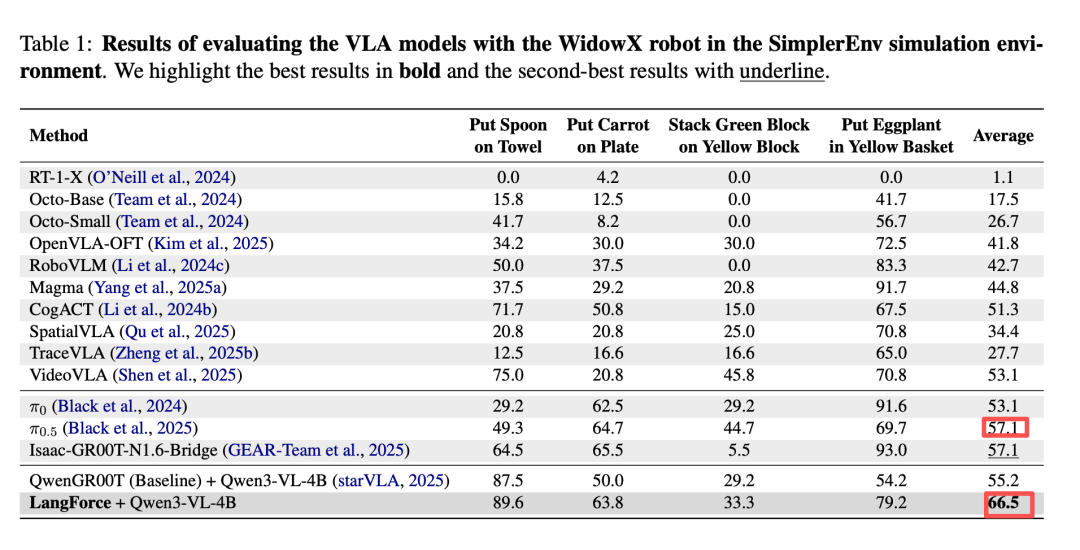
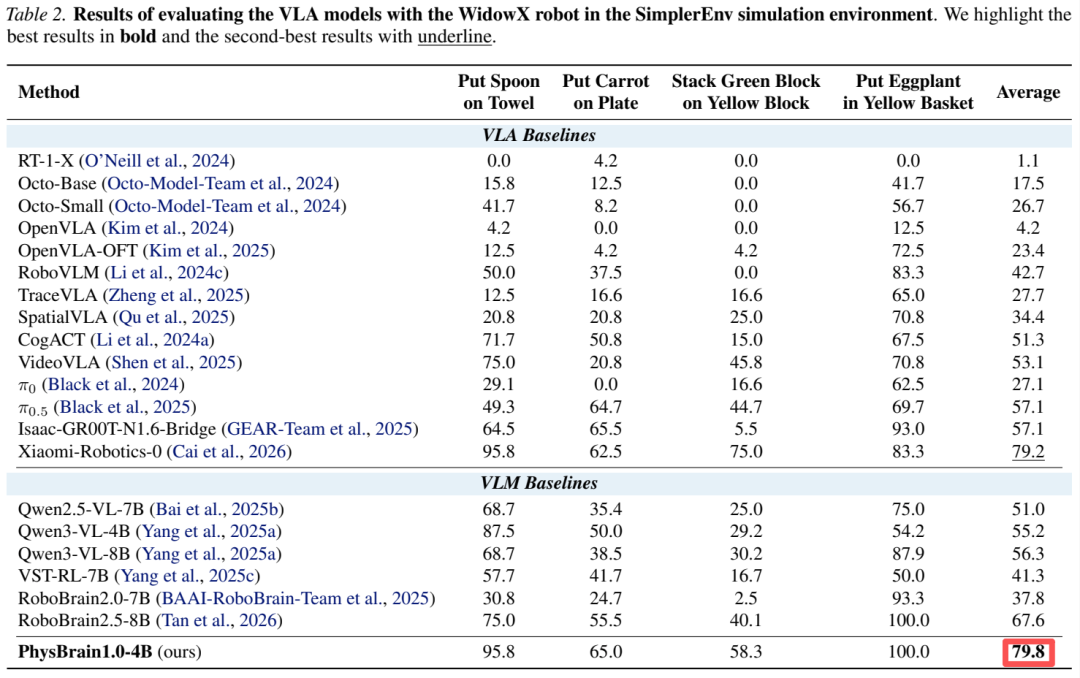
利用这套方法,他们构建了数据集 E2E-3M,并用该数据集训练了一个具身大脑 ——PhysBrain。在完全未出现在训练集中的 SimplerEnv 四个操作任务上,PhysBrain(8B 版本)以 67.4% 的平均成功率力压行业标杆、Physical Intelligence 的 Pi0.5,领先优势达 10%。
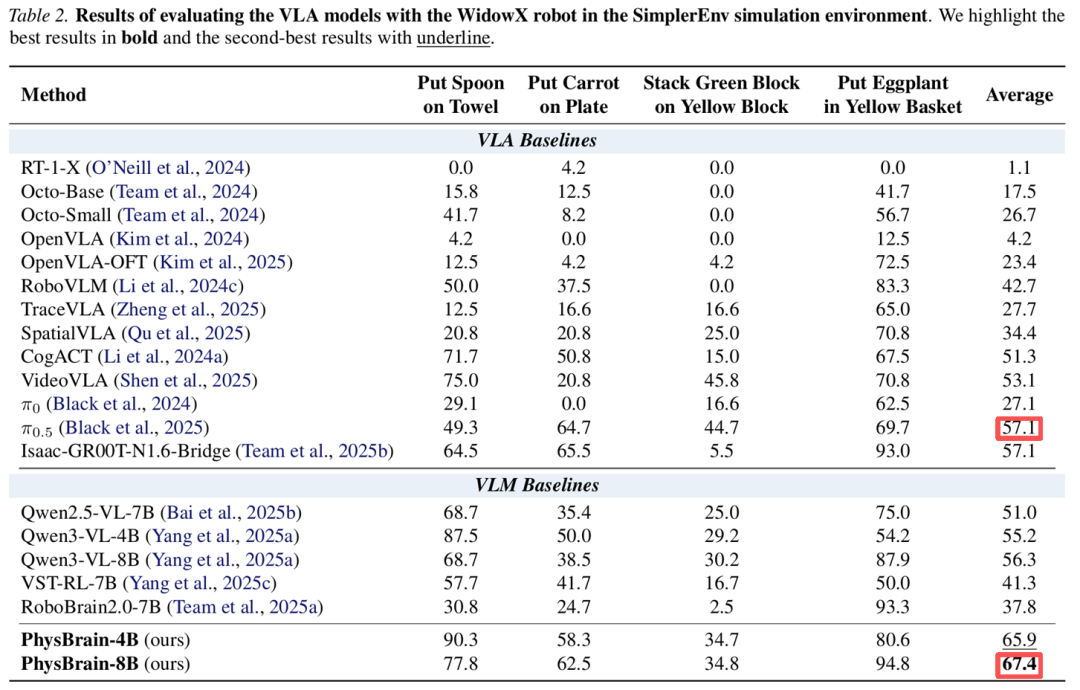
要知道,PhysBrain 的微调数据仅为千小时的纯人类视角视频(即 E2E-3M 的体量)和部分通用 VQA 数据,不含机器人轨迹数据,就让模型掌握了空间结构和物体动力学特征,展现了良好的泛化性;相比之下,Pi0.5 则是用数万小时真机轨迹数据「堆」出来的。这有力地证明了:一个深刻理解物理世界规律的「聪明大脑」,其学习效率与泛化上限远超轨迹拟合。
更令人惊叹的是,PhysBrain 在仅学习「成功案例」的情况下,竟自发涌现出了灵活策略能力和自动纠错能力。
在 SimplerEnv 的胡萝卜抓取任务中,模型接到的指令只是把胡萝卜放进盘子里。第一次夹取失败后,它并没有机械地重复同一个抓取动作,因为模型发现夹爪已经碰到了胡萝卜,于是顺势改为用夹子把胡萝卜往盘子方向推,一次推不进去,又加大力度重新推了一次。后来,发现这种方式依然无效,它又主动切换策略,重新调整姿态去抓取。要知道,「推」这个动作是没有包含在模型训练数据里的,它也没有看到过失败轨迹示范,这种表现更像是一种对物理交互的直觉式理解。