


SWE-Vision团队 投稿
量子位 | 公众号 QbitAI
多模态大模型在代码能力上进步惊人,但在基础视觉任务上却频繁失误。
活跃在AGI基础研究前沿的技术团队UniPat AI构建了一个极简的视觉智能体框架——SWE-Vision,让模型可以编写并执行Python代码来处理和验证自己的视觉判断。在五个主流视觉基准测试中,SWE-Vision均达到了当前最优水平。
模型看得见,却没法精确处理
多模态大模型的代码能力在过去一年取得了惊人进展——独立搭建项目、排查bug、完成复杂重构,表现已可比肩资深工程师。然而在“理解视觉世界”这件事上,它们的表现远没有代码能力那样可靠。UniPat AI此前发布的多模态基准BabyVision就揭示了这一现象:模型常常给出大段看似合理的推理,却在最基础的计量、计数和空间关系判断上出错。
UniPat AI此前发布的多模态理解benchmark BabyVision已被多个近期发布的重磅模型产品纳入评测体系,并在其技术报告中被引用,体现了社区对这一问题的广泛关注。
当研究团队仔细审视BabyVision中模型出错的案例时,可以发现一个关键点:问题往往是“模型看见了,却无法精确处理”:
阅读柱状图时,模型能感知到“大约75%”,但无法精确计算比值;
在复杂场景中计数时,模型可能识别了每一个物体,但在逐一清点时出错;
描述空间位置时,模型能给出定性判断,但难以稳定进行距离计算和几何推理。
面对这些错误,人类通常会怎么做?
掏出工具:画辅助线、作出标记、用尺测量、用笔计算。
这个观察引发了一个关键猜想:既然模型已经极其擅长编程,能否让它用代码——这个它最熟悉的工具——来弥补视觉处理中的精度短板?
SWE-Vision正是对这一猜想的系统性验证。
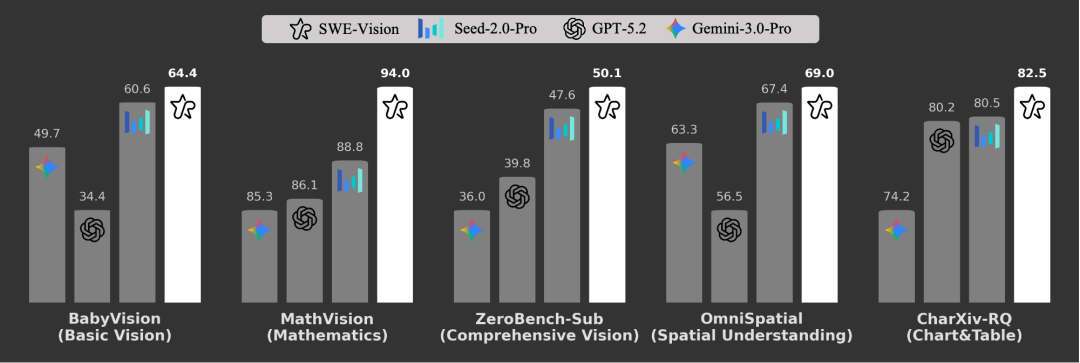
其结果令人瞩目:在五个不同的视觉基准测试中——涵盖基础感知、图表推理、数学问题解决、空间理解和复杂的多步骤视觉挑战——SWE-Vision始终改进了前沿LLM,如GPT-5.2-xhigh和Seed-2.0-Pro,并取得了最先进的结果:在BabyVision上达到64.4,在MathVision上达到94.0,在Zero-Bench-Sub上达到50.1,在OmniSpatial上达到69.0,在CharXiv-RQ上达到82.5。
SWE-Vision是什么:一个“极简视觉智能体”
SWE-Vision并不需要再造一堆专用视觉工具,而是把要做的事压缩到极简:
1. 工具层:只保留两个工具
config.py里定义的工具只有两个:execute_code和finish。
execute_code:让模型在一个可持续保留状态的Jupyter环境里执行Python
finish:当模型确信答案正确时输出最终答案
这里最关键的不是“能执行代码”,而是工具接口本身非常小、非常通用。SWE-Vision没有给模型塞一堆专用视觉API,而是只暴露一个模型本来就很熟悉的动作:写Python。
2. 控制层:一个标准的agentic loop
agent.py里的VLMToolCallAgent实现了完整的循环:先把用户问题和图片组织成消息;然后调用支持tool use的聊天接口;如果模型发起execute_code,就把代码送到notebook内核执行;再把执行结果作为tool message回流给模型;模型据此决定继续调用工具还是finish。
repo里默认tool_choice=”auto”,并支持reasoning模式;在开启时会把推理effort设为高档,并允许最多100轮迭代。
3. 执行层:Docker里的持久化Jupyter kernel
kernel.py不是简单exec()一段代码,而是正经启动一个Docker容器,再在容器里拉起ipykernel。宿主侧通过jupyter_client.BlockingKernelClient连接这个内核,并从IOPub / shell通道收集执行结果。
内核是持久化的,变量、导入、图像对象和中间结果都能跨多次execute_code保留;同时代码运行在隔离的Docker环境里,宿主与容器通过挂载目录交换文件。kernel.py还会在启动后做health check,并把matplotlib后端配置成inline,以便抓取图像输出。
简单来说,SWE-Vision不强迫模型每题都写代码,但给它一个随时可用并且熟悉的“视觉工具库”。
一次请求在系统里到底怎么流动:从看图推理到带图循环验证
SWE-Vision像一个会看图的数据科学家,其完整工作流如下:
用户给问题+图片
模型先思考:这题能不能直接答?需不需要计算/验证?
需要就调用execute_code:在Notebook里用PIL / NumPy / matplotlib等做分析
代码输出(数值/报错/可视化图)回流给模型
模型继续迭代,直到调用finish给最终答案
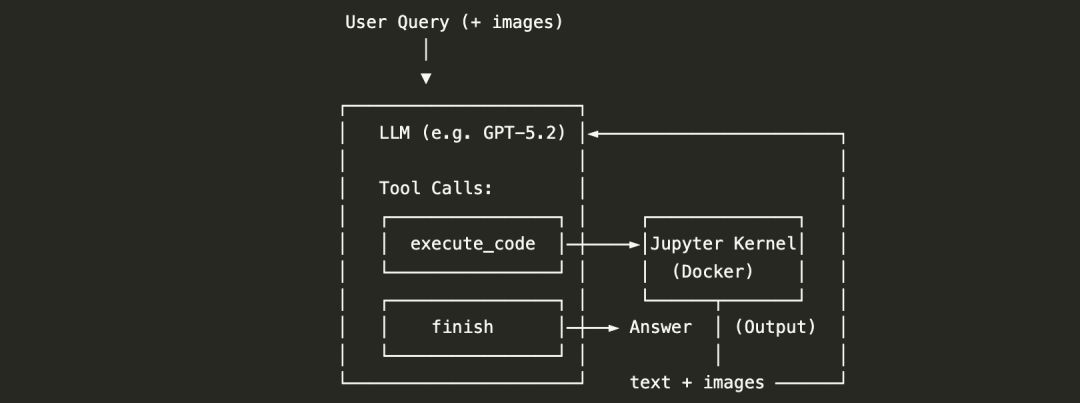
它有几个关键设计:
有状态的执行环境:变量、导入、图片加载都能跨多次调用保留
Docker沙箱:确保可控安全环境+复现性;
Image-in/Image-out:意味着模型不仅能读取输入图像,还能将自己生成的可视化结果回传给自身进行验证——这是实现自我纠错的关键;
OpenAI function calling标准接口:保证了与主流模型的开箱即用兼容性。
这套设计的价值在于:允许模型像一个真正的科学家一样,先做实验再下结论。
为什么stateful notebook比一次性code executor更关键
很多人第一次看SWE-Vision会觉得,它不过是在VLM外面加了个Python工具。真正的差别其实在于stateful。
在SWE-Vision中内核状态会在多次调用间保留;这意味着模型可以像人类分析师那样分步工作:第一轮先读图、检查尺寸;第二轮裁剪局部、看边缘;第三轮统计颜色或测距离;第四轮画辅助线做确认;最后再生成答案。
如果代码执行是无状态的,这种多步分析会非常笨重:每一步都要重新导入库、重载图片、重建变量,模型也更难维护中间假设。SWE-Vision通过持久化kernel,把“多轮工具调用”变成了“同一个notebook会话里的连续实验”。从工程实现上看,这也是它为什么能处理图表测量、空间关系和复杂多步视觉任务,而不只是做一次性的OCR或检测。
SWE-Vision的关键在于“能验证自己的视觉判断”
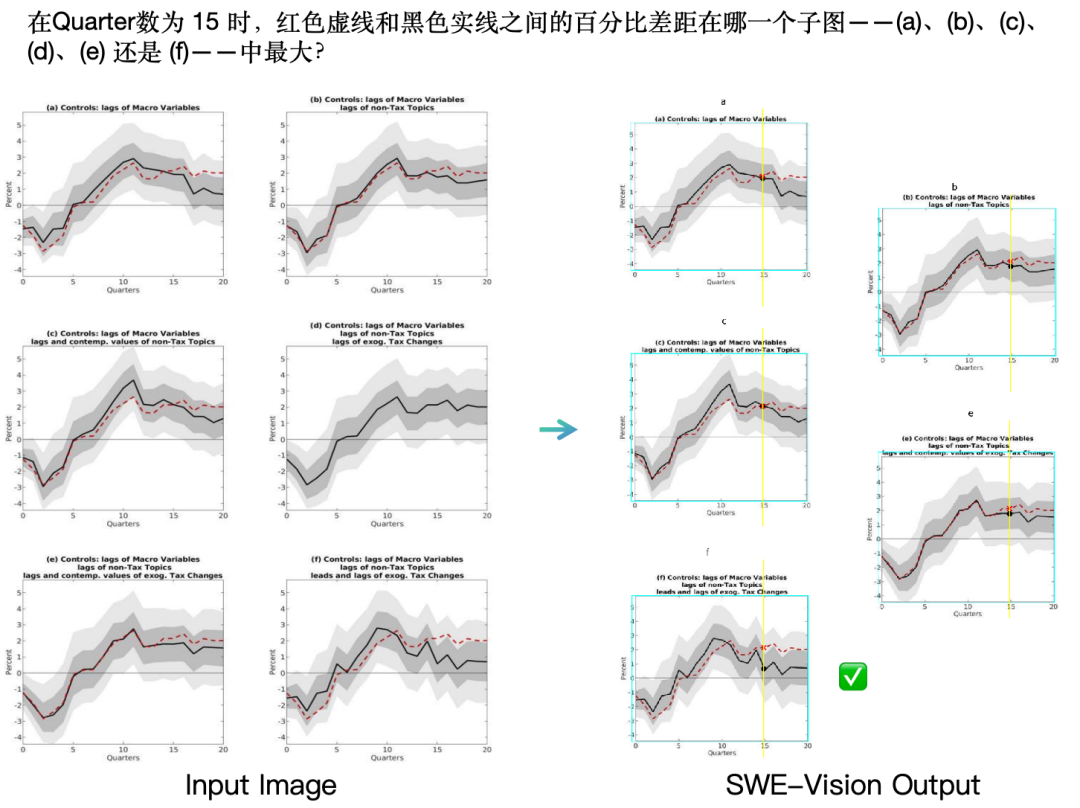
在SWE-Vision「观察科学图表、总结规律」的案例中,研究团队发现了一种截然不同的行为模式。如下图所示,这是科研场景中常见的图表分析任务:要求模型判断,在Quarters = 15时,哪一张子图中红色虚线与黑色实线之间的差距最大。
SWE-Vision智能体给出了一套极其严谨且可解释的解法。首先,它排除了不存在红色虚线的子图(d);随后,对每一张候选子图在Quarters = 15处精确绘制辅助线,定位红线与黑线的交点;接着,通过可执行代码精确计算两条曲线在该位置的数值差距;最终基于计算结果给出正确答案。
这种“先结构化分析、再程序化测量、最后数值验证”的思维与行动闭环,与传统视觉语言模型依赖直觉式“瞪眼观察”直接给出答案的方式形成鲜明对比。它不仅显著提升了结果的可靠性与可解释性,也展示出更高的能力上限与更强的泛化潜力。
为什么极简设计反而更强
SWE-Vision的一个重要结论是:对视觉任务而言,加入通用代码工具,是提升前沿多模态模型视觉能力的一个有效test-time scaling方向。
它之所以有效,恰恰在于其极简:
工具数量少,决策边界清晰;
工具语义与模型已有能力高度一致;
支持多轮迭代和状态积累;
中间结果可被再次观察,而不是一次性返回文本;
不绑定某个特定benchmark的专用手工策略。
这与很多“为了某类视觉任务单独发明一套工具接口”的方法不同。这些方法往往在某些窄任务上能提升,但泛化性不足;而SWE-Vision的目标,是提供一个尽可能通用的视觉增强框架,让模型自己决定何时调用代码、如何组织分析步骤。
五大基准全线提升:更加通用的“视觉能力增强器”
SWE-Vision在五个覆盖面很广的视觉基准上进行了评测(基础感知、图表、数学、空间、综合多步推理),核心发现高度一致:引入代码执行能力,能系统性地抬升前沿模型的视觉表现上限。
在对比实验中(同一模型vs SWE-Vision),SWE-Vision对两个前沿的视觉语言模型(GPT-5.2,Seed-2.0)都带来显著提升:
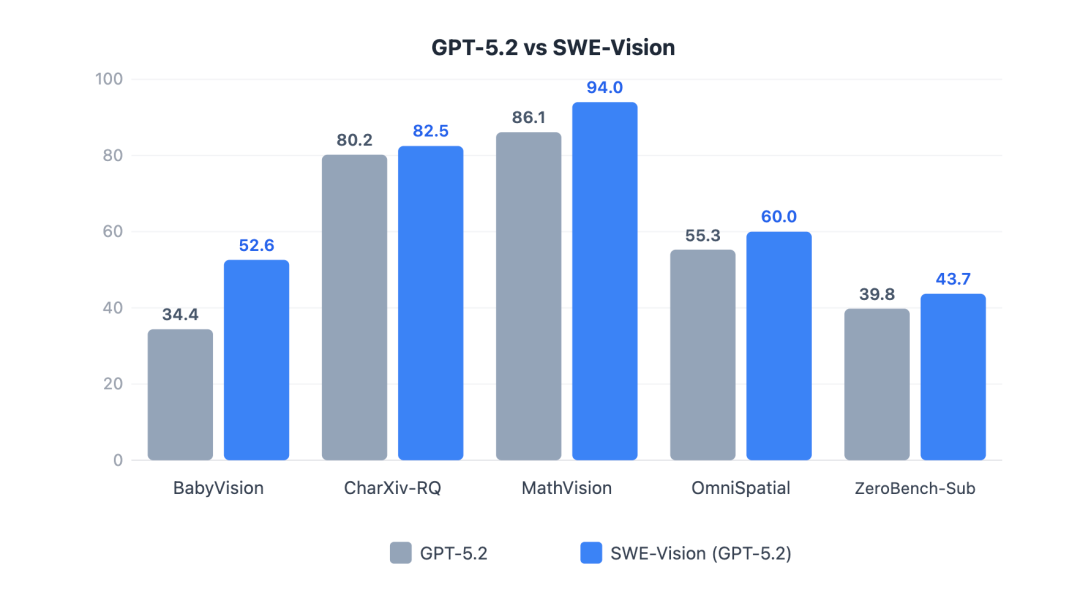
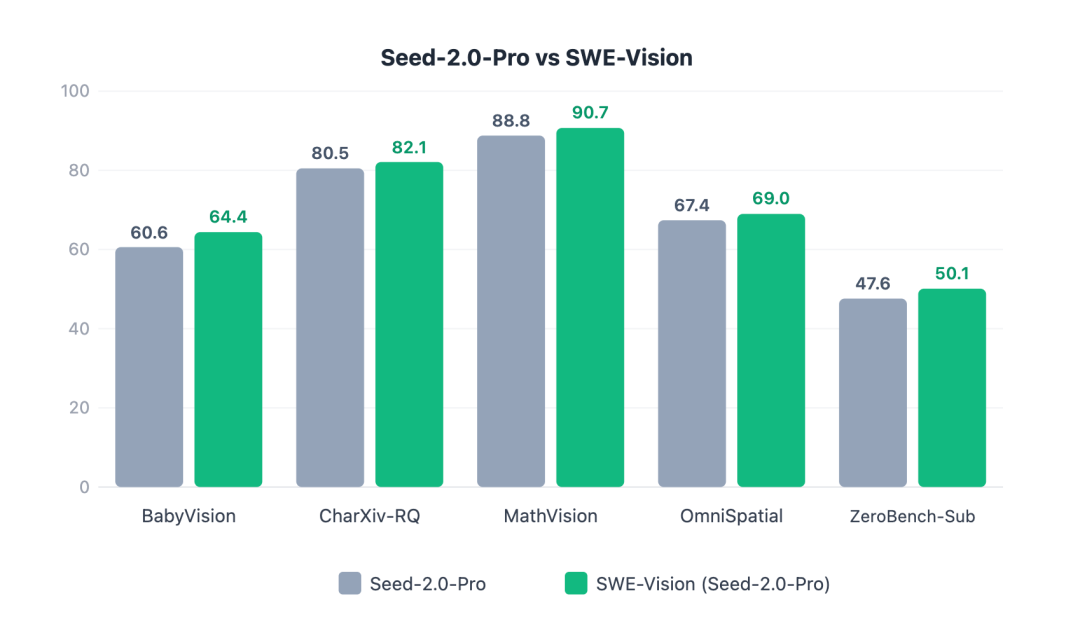
“反直觉”的一点是:
提升幅度最大的,往往不是最复杂的高阶推理任务,而是最基础的感知和精确处理能力——例如BabyVision中的计数、颜色识别和空间关系判断。这类任务人类靠直觉加简单工具就能稳定完成,而模型仅凭“语言化视觉”则极易忽略细节、数错个数、缺乏验证手段。
SWE-Vision的结果揭示了另一种可能:
对于视觉来说,测试时扩展(test-time scaling,TTS)不一定只能靠“多想几段文字”,也可以靠“多写几行代码”来看得更精细。
未来的发展方向:让“代码增强视觉”变成视觉智能体的原生能力
与用于训练多模态LLMs的传统数据(基本上是问题,图片,答案三元组)不同,训练视觉智能体模型需要多模态交错的智能体轨迹。它还需要一个交互式环境来支持强化学习、工具使用和评估,使模型不仅能学习回答问题,还能学习感知、行动和反思,要彻底释放“工具增强视觉”的潜力,模型需要更多深度交织的视觉-编程SFT/RL数据与环境,来学会感知、行动和反思。
具体而言,下一步的关键方向包括:
判断时机:学会识别何时视觉推理需要代码辅助,何时可以直接回答
中间验证:在多步推理过程中主动检验中间结果的正确性
失败恢复:在代码方案无效时及时跳出,切换到替代策略
原生融合:让“观察”与“计算”不再是两个独立步骤,而是深度融合,一体两面
SWE-Vision的开源代码和全部实验数据已在GitHub发布。编程辅助的精确视觉理解是一个值得社区共同探索的方向——五百行代码的极简框架,也许是这段旅程一个不错的起点。
官网:
https://unipat.ai
Blog:
https://unipat.ai/blog/SWE-Vision
开源地址:
https://github.com/UniPat-AI/SWE-Vision
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓
感兴趣的小伙伴欢迎关注 👉 了解详情

🌟 点亮星标 🌟
科技前沿进展每日见