


田晏林 发自 凹非寺
量子位 | 公众号 QbitAI
从特斯拉擎天柱团队离职创业一年多,杨硕终于打破沉默。
在成为Mondo Robotics(妙动科技)联合创始人、CTO后,很多人都好奇,他从创业到现在为什么一点消息也没有,以及这家公司究竟在做什么。
这不,最近妙动科技团队就带着新论文《DiT4DiT: Jointly Modeling Video Dynamics and Actions for Generalizable Robot Control》来了。

过去一年,杨硕团队主要研究一件事:
用视频来训练机器人的动作,让机器人少学数据,还能高水平发挥,同时适配各种新场景,以此来解决VLA模型不懂物理的问题。
他们还给这款能同时处理视频动态和机器人动作、靠专属目标函数实现“从视频到动作”一步到位训练的智能模型,起了一个直观且凸显核心架构的名字——DiT4DiT。
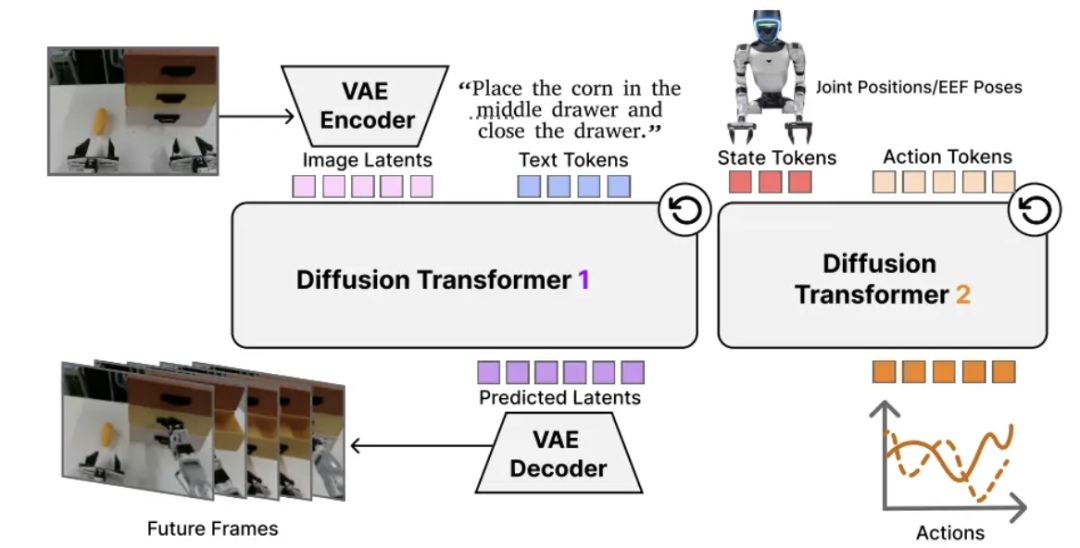
DiT4DiT也是目前world model在人形机器人上第一次落地,之前业内有一些机械臂控制算法落地,但都没在人形机器人身上跑通。
论文发出后,包括Agility Robotics的AI负责人在内的不少硅谷机器人专家,在推特上转发了他们的工作。
什么是DiT4DiT?
简单讲,这是一个端到端的机器人学习视频动作的模型,将视频扩散(video DiT)和动作扩散(action DiT)整合到一个级联框架中。
这个研究中,有两个关键设计:中间去噪、三个“时间步”(timestep)方案。
中间去噪是整个研究最核心的设计。
具体思路是:不等待视频生成模型完全输出“完整的未来画面”,而是在生成过程中(也就是“去噪”的中途)提取关键特征,用这些“半成品特征”指导机器人动作决策。
用一个生活化的例子来理解。现要求机器人完成“把杯子放进抽屉”的任务。
传统方法是让视频模型生成“杯子被放进抽屉”的完整视频,机器人再根据这个完整视频推导自己的动作。
而中间去噪,就像机器人在大脑里“构思”整个任务的过程中,刚想清楚“杯子该移动到抽屉上方”这个关键步骤,就立刻提取这个关键信息,直接推导“伸手、移动到抽屉上方”的动作,不用等整个任务画面全部构思完。
再给大家分三步捋一下过程:
第一步:先让视频模型处理画面,也就是视频生成的去噪过程。
就像一张充满噪点的图片,谁都看不清,必须逐步去噪才行。这个“逐步去噪”的过程会经过多个阶段,每个阶段都会让这张图变得更清晰一些。每次降噪,我们都能看到不同程度的“未来场景信息”。
第二步:DiT4DiT通过一个“钩子机制”(类似在视频模型的中间层装个探测器),在去噪过程中的特定阶段(不是开头,也不是结尾),提取物体运动的关键特征。
第三步:不用再依赖完整的未来视频,而是把这些提取的中间特征传给动作模型,直接生成精准的控制指令。
关于“中间去噪”,论文中还有两个有意思的结论。
他们做了一个消融实验,明确:
(a)提取第18层(中间偏深的层)的特征效果最好;
(b)使用不同的去噪步数(从1步~32步),发现“只进行1步去噪”提取的视频特征效果最好。
第一个结论指向“从视频的哪个位置提取特征”;第二个结论指向“在去噪的哪个阶段提取特征”。
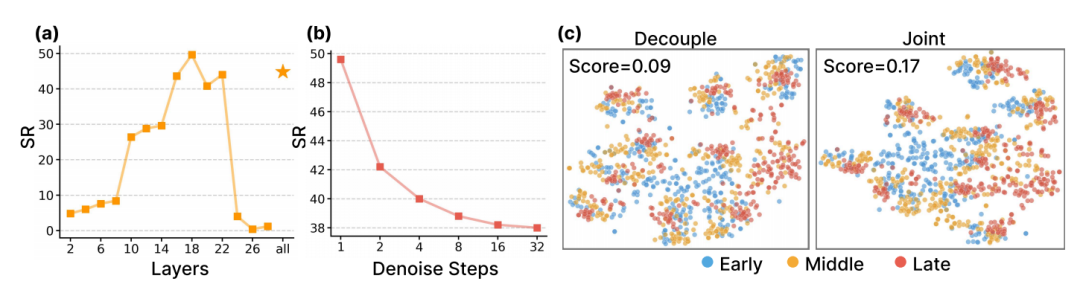
这是DiT4DiT视频特征提取的两个独立参数,但两个结论的底层逻辑高度一致:都是为了避开“表层无价值信息”和“过度像素细节”的干扰。
简单讲,为何要从第18层提取信息?是因为浅层仅编码,只知道桌子上的物体是“红色、圆形、光滑”的,但不知道是杯子→属于没有用的信息;
深层会过度聚焦像素,死死盯着“杯子像素的各种细节”,比如杯口反光点到底由3个还是4个像素组成、相邻两帧的杯子像素偏移了0.01个点要不要修正,但不知道让杯子进入抽屉要怎么移动→属于捡芝麻丢西瓜。
进行1步去噪,也是同理——并不是图像越清晰,行动力越强。
当画面完全清晰后,机器人会发现放进抽屉的是一个红色圆柱形玻璃杯,那么当一个蓝色正方形塑料杯摆在它面前时,行动可能就会出错。
而中间降噪+1步提取视频特征,因为提取的是“物理规律”(比如“放东西需要先靠近目标”)而非“具体画面”,当遇到不同颜色、不同形状的杯子时,机器人都能通过规律推导,正确完成“把被杯子放进抽屉”的指令。
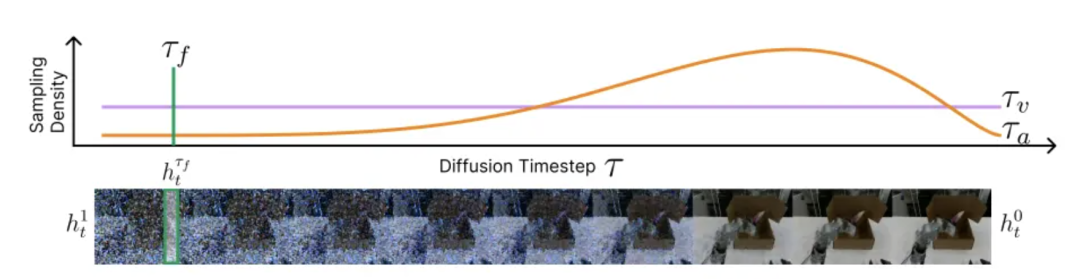
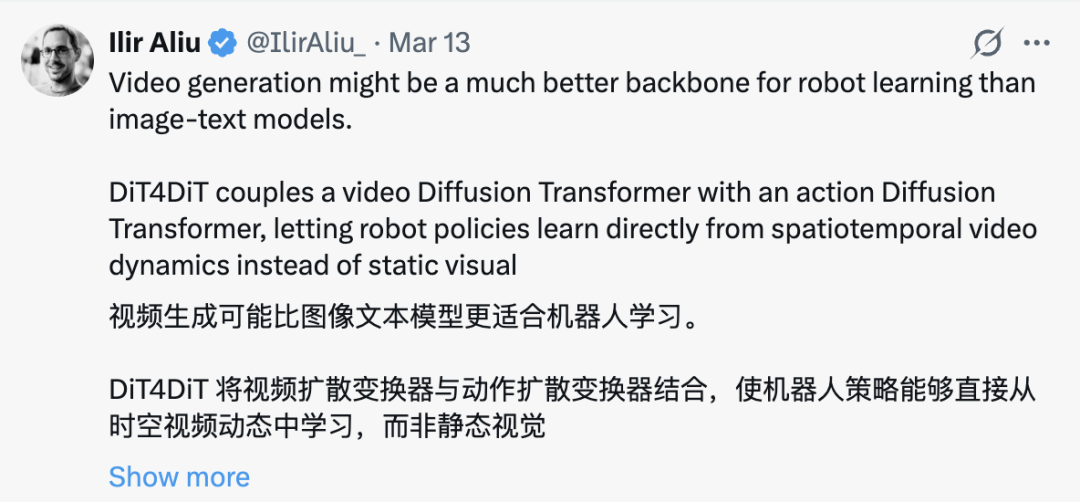
再看第二个关键设计:三时间步方案(上图所示)。
这个方案是为解决“视频生成”和“动作预测”两个任务的传统训练痛点:视频模型想快点生成,动作模型想慢点学习,二者互相干扰。
为了让二者既能独立高效工作,又能配合默契。DiT4DiT分配了三个独立的时间步:
视频生成时间步(τᵥ):按自己的均匀节奏学“怎么生成未来画面”,保证能力全面;
特征提取时间步(τբ):按固定节奏“截取”稳定的中间信息,作为两者沟通的桥梁;
动作生成时间步(τₐ):让动作模型聚焦关键的节奏,学习“怎么根据信息生成动作”,保证精度高效。
让两个任务在各自最舒服的节奏下工作,同时通过固定的特征提取时间步,实现高效配合。
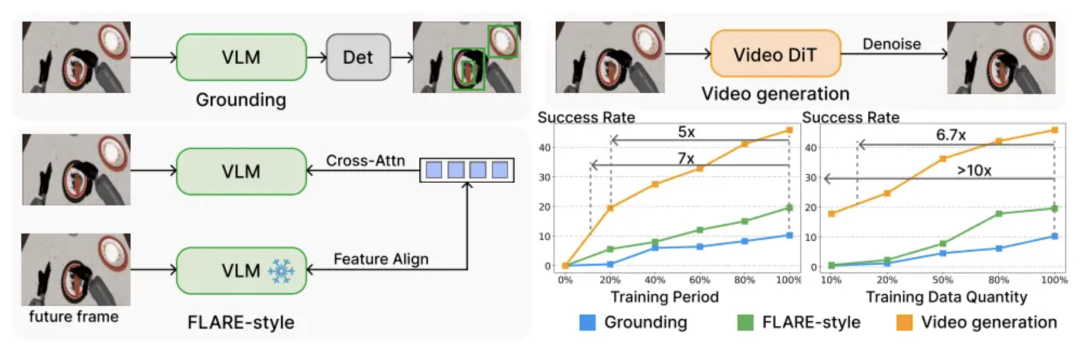
妙动科技团队对比了三种训练范式后发现(上图):这种视频生成方案的收敛速度提升7倍,数据效率高出10倍以上。
LIBERO基准的核心实验结果显示:DiT4DiT在LIBERO上达到98.6%的平均成功率,直接证明模型的SOTA表现。
为什么要这样训练机器人?
值得注意的是,这套方案还有一个关键突破:他们的模型中没有用腕部相机,所有的画面都是机器人主视角采集的。
因为DiT4DiT是world model在人形机器人上最接近实际使用场景的落地方案。
之前业内有一些在机械臂上使用的world model方案,但都没在人形机器人身上跑通。
宇树去年发布了使用三相机方案(头部和双手各一个),在人形机器人上部署的UnifoLM。
但这样的硬件方案会大大增加系统的复杂度,仅使用头部相机在人形机器人上部署的方案之前还没有出现过。
不过大家也不必担心没有腕部相机无法保证精度,因为实验发现,在world model范式中,主视角相机也足够做出同等(甚至更好)的效果。
为什么要这样训练机器人?本质还是为解决之前机器人学习里一直存在的两个问题。
一是传统视觉-语言-动作(VLA)模型虽为机器人学习的主流范式,但这种模型的核心底子,是用静态的图片和文字练出来的,压根学不会现实世界里那些动态的物理规律,比如东西怎么动、不同物体碰在一起会有什么反应。
但机器人干活,最后拼的就是对物理世界的理解。
还是让机器人把杯子放进抽屉。
传统VLA模型教学,只能靠反复摆杯子、放杯子的海量标注数据慢慢试错学,不仅要教上百上千次,还容易学“死”。换个杯子或者抽屉,机器人可能就不会了,导致机器人学东西效率极低。
二是生成式视频模型存在研究空白。之前的训练方法只把它当辅助,顶多让它生成几段放杯子的视频当训练素材,或者从视频里抠点简单特征,从没让它直接指导机器人的动作。
但生成式视频模型,天生知道“把杯子放进抽屉”这个过程里的运动和物理逻辑。最终机器人学起来特别快,不用练几百次,换个杯子、换个抽屉也能零样本适配。
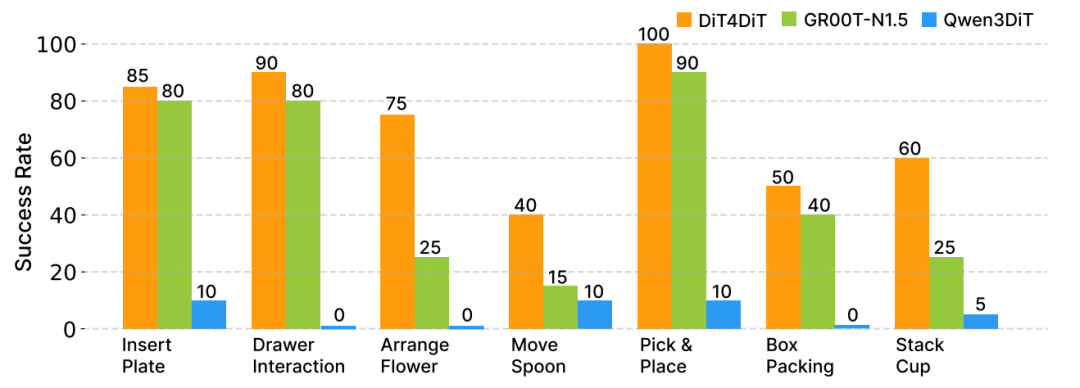
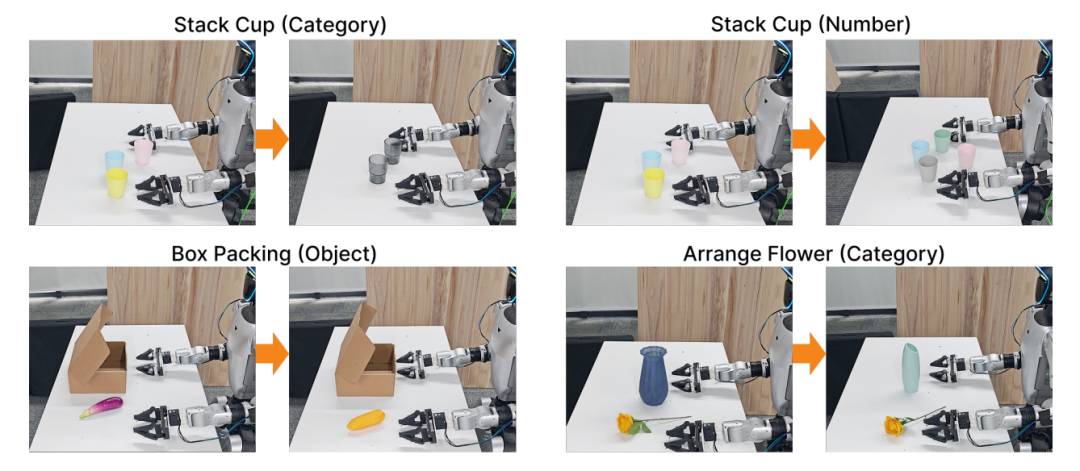
他们在宇树科技G1人形机器人上部署了DiT4DiT,进行7个场景的任务测评,包括插花、打包盒子、移动勺子、叠杯子、抽屉交互等。
成绩非常不错,DiT4DiT模型的性能全面优于预训练的GR00T-N1.5模型,以及参数匹配的Qwen3DiT基准模型。
而且和近期出现的另一种机器人控制方案Cosmos Policy相比,妙动的方案整体模型参数2B左右,可以在RTX 4090显卡上实现6Hz推理速度;而Cosmos Policy必须用H100专业算力卡,才能达到1Hz推理效率。
换句话说,妙动的方案有更好的部署在机器人端侧芯片上的潜力。
论文团队介绍
最后介绍一下这项研究的作者团队,一共7位,来自妙动科技、香港科技大学(广州)和香港科技大学三个机构。
其中,Teli Ma、Jia Zheng、Zifan Wang,同时隶属于妙动和香港科技大学(广州)。
梁俊卫(香港科技大学教授)和杨硕是本文的共同通讯作者,同时承担共同指导工作,负责论文的整体方向、实验设计与学术把关。
说回杨硕。早年他曾在大疆担任技术总监,后赴美深造,从CMU博士毕业后,在特斯拉Optimus团队工作了一段时间,也是特斯拉擎天柱团队非常知名的离职创业的中国人。
2025年1月,妙动科技成立,主营消费级机器人,法定代表人、董事长是高建荣。
他是杨硕在大疆时期的同事,也是大疆历史上最年轻的高管,曾做过大疆供应链和市场部的负责人,大疆教育BU负责人,和杨硕一同负责过大疆的机器人赛事机甲大师。
在高建荣注册公司的三个月后,杨硕官宣离职特斯拉,成为妙动科技联合创始人兼CTO。

作为知乎大V,杨硕在2025年12月底发过一篇文章,回忆了自己和家人在匹兹堡和硅谷的工作生活,讲述了回国创业后,每天清晨挤入地铁上班的场景。
当然,这份年终总结也提到了2024年~2025年对他打击最大的事情,当属机器人学界关于人形机器人全身行走运动控制应该采用模型预测控制(MPC)还是强化学习(RL)的争论。
2024年整年里,我在特斯拉使尽平生所学,想把MPC用在全尺寸人形机器人Optimus上……然而这些都没什么用。年尾,痛定思痛,切换成了时下最流行的强化学习RL技术,之后仅用了一个多月的时间就调出一个神经网络控制器让机器人跑步上山,此时我的震惊之情难以言表。
杨硕介绍,当前,妙动科技的技术团队大量使用了强化学习和深度学习技术开发机器人的运动控制器和操作控制器,“我们已经做出了一些很棒的产品原型、运动算法和人形操作模型方面的成果可以在2026年公布。”
事实上,这篇论文正是妙动科技研发体系的重要佐证。
不过,也有用户反馈这个模型存在周期性的卡顿,认为可能有推理错误。

对此,杨硕回复称:“这不是bug。这是因为VAM推断速度非常慢,因此尽管有平滑机制,机器人仍会接收到不连续的轨迹。我们需要通过压缩模型来提高推理时间。”
代码即将发布,论文链接已贴在下方,感兴趣的朋友可以细读。
参考资料:
[1]https://dit4dit.github.io/
[2]https://my.feishu.cn/wiki/G8BMwxbfmiBLlYkc58KcIF76nxb
[3]https://www.zhihu.com/people/yyss2037/posts
— 欢迎AI产品从业者共建 —
📚「AI产品知识库」是量子位智库基于长期产品库追踪和用户行为数据推出的飞书知识库,旨在成为AI行业从业者、投资者、研究者的核心信息枢纽与决策支持平台。

一键关注 👇 点亮星标
科技前沿进展每日见