


GTR-Turbo团队
量子位 | 公众号 QbitAI
多模态智能体在多轮复杂任务里,跑着跑着会“忘了自己是谁”。
这叫“思维崩塌”,是目前普遍存在的现象,对应用落地影响很大。
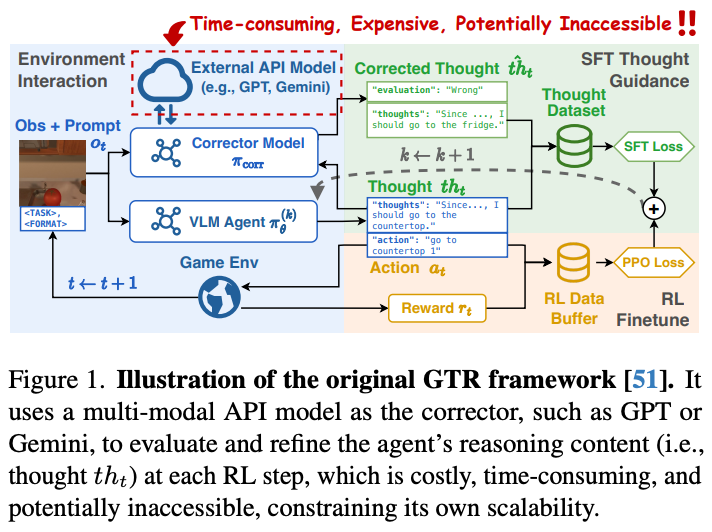
为此,早前研究团队提出的Guided Thought Reinforcement(GTR)框架通过引入外部“修正器模型”提供过程引导,有效缓解了这一问题。然而,GTR以及同期工作On-Policy Distillation(OPD)均依赖于强大的外部教师模型(如GPT、Gemini)提供过程指导,带来了巨大的训练成本开销和潜在的隐私问题,大大限制了方法的可扩展性。
近日,这个由清华、北大与腾讯的研究者组成的团队推出了性能更强、成本更低的升级版框架:GTR-Turbo。该研究揭示,无需任何外部专家模型,仅通过融合训练过程中的历史检查点,就能得到一个“免费且强大”的教师模型。GTR-Turbo能够在保持甚至超越原版GTR能力的基础上,最高降低50%的训练时间和60%的成本,实现了VLM智能体的低成本自驱动进化。

从“寻求外援”到“内生进化”:GTR-Turbo的核心演进
GTR和OPD代表了当前VLM智能体训练的先进范式:通过引入更强的教师模型提供细粒度的过程指导,有效缓解了多轮强化学习中奖励稀疏和长程信用分配的难题。然而,这类方法存在明显局限:
高昂的成本:调用GPT或Gemini等API模型需要大量费用
训练时间延长:每步RL都需要查询外部模型,显著增加等待时间
可及性问题:前沿模型可能无法获取或存在使用限制
GTR-Turbo的核心思想是将“外部求助”转变为“内部进化”。研究团队发现,RL训练过程中产生的历史检查点本身就蕴含着丰富的经验,通过对这些检查点进行权重合并,可以形成一个非常稳定且能够超越当前训练智能体的教师模型。这个“免费老师”能够为当前的智能体提供步级(Step-wise)的思维引导。
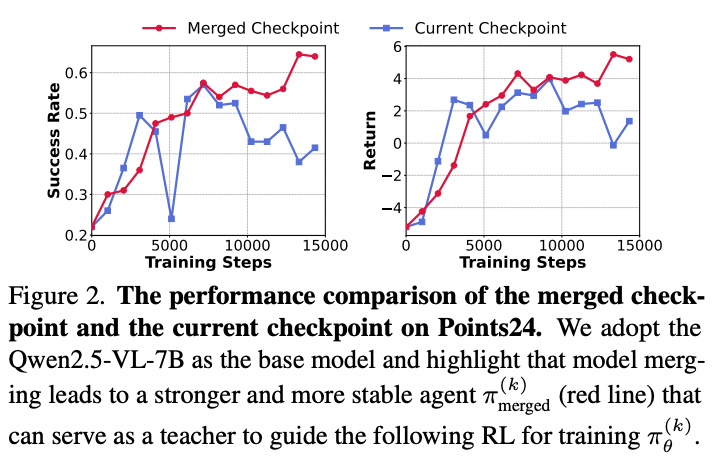
这一设计的优势在于:
零成本开销:完全摒弃了昂贵的外部API调用,实现了全本地化的闭环训练。
精准的指导:教师模型源于智能体自身的历史基因,其给出的指导逻辑天然贴合当前任务分布,引导更加精准高效。
自适应进化:随着智能体自身能力的提升,融合出的教师模型能力也会水涨船高,始终在当前能力的边缘提供有效的监督信号。
GTR-Turbo框架的具体流程
GTR-Turbo的整体框架延续GTR“思维+动作”联合训练的思想,采用“SFT/OPD + RL”的模式,有效抑制RL训练中常见的“思维崩塌”现象,保持智能体思路的多样性与稳定性。研究团队设计了两种变体:
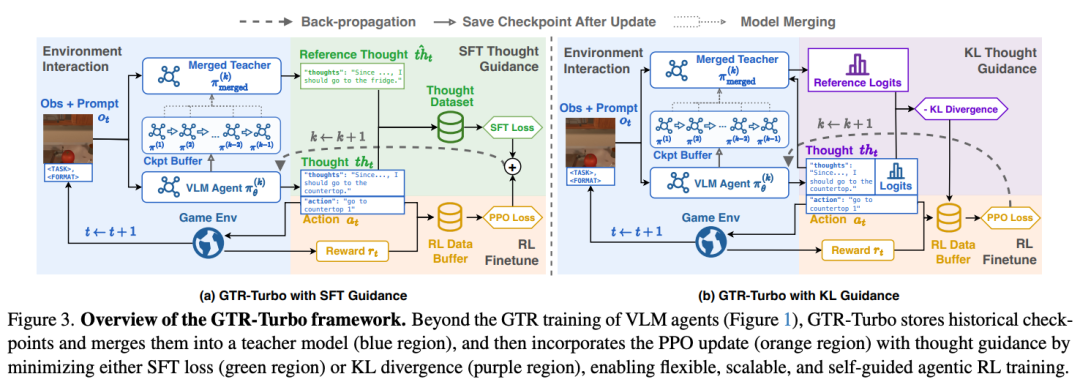
SFT变体与原始GTR类似,通过监督微调的方式将教师模型的指导融入训练:
教师模型针对当前的状态输入给出参考的思路
在PPO损失的基础上,增加针对思维token的SFT损失
通过DAgger策略缓解在线训练中的分布偏移问题
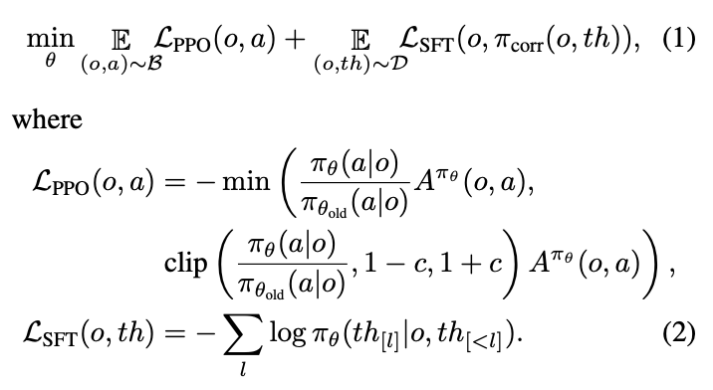
KL变体则采用标签蒸馏的方式,具有更高的训练效率:
使用反向KL散度衡量学生模型与教师模型的输出分布差异
仅需单次前向传播即可计算指导信号,无需自回归生成
相比SFT约束更松,天然鼓励探索

训练过程中,每完成一轮PPO更新,模型权重即被保存下来。通过SMA(Simple Moving Average)或者EMA(Exponential Moving Average)的策略合并检查点并更新教师模型,GTR-Turbo实现了完全自主的“教学相长”循环。
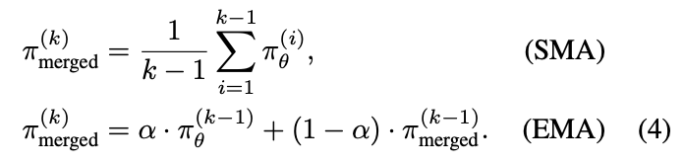
GTR-Turbo的实验效果
研究团队在Points24卡牌游戏和ALFWorld具身智能环境两个具有代表性的视觉智能体任务上进行了实验评估。模型采用Qwen2.5-VL-7B,以纯PPO强化学习的RL4VLM方法和借助GPT-4o进行思维引导的GTR方法作为基线进行比较。
在需要专业数学知识进行视觉推理的24点游戏中,GTR在早期通过外部知识获得一定优势,但GTR-Turbo也能够保持思路完整和训练稳定,最终实现超越并达到了53.5%成功率的SOTA性能,相比GTR取得了将近10%的巨大提升。
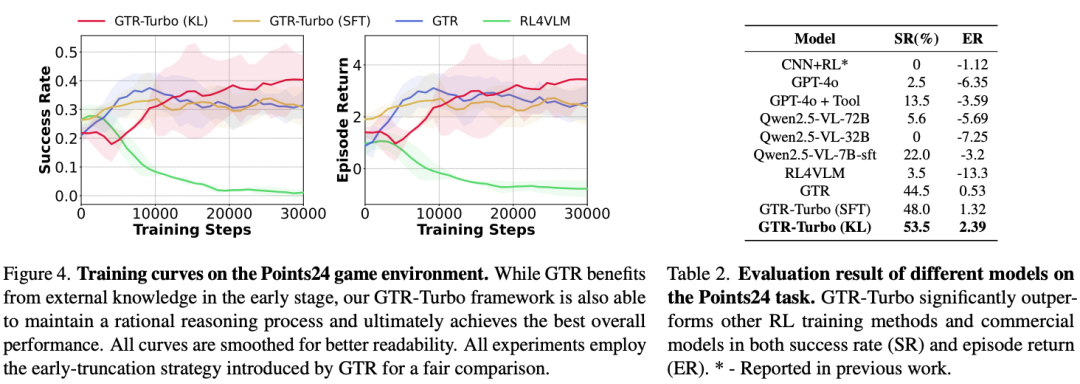
而家用机器人场景的具身智能任务ALFWorld,其任务长度可能超过50步,每一步可能有20余种可行动作,且奖励极其稀疏,因此对多模态智能体而言是一个非常复杂困难的环境。GTR-Turbo能够仅依靠自身的探索、经验积累和思维引导,达到与依赖外部知识的GTR相同的表现。
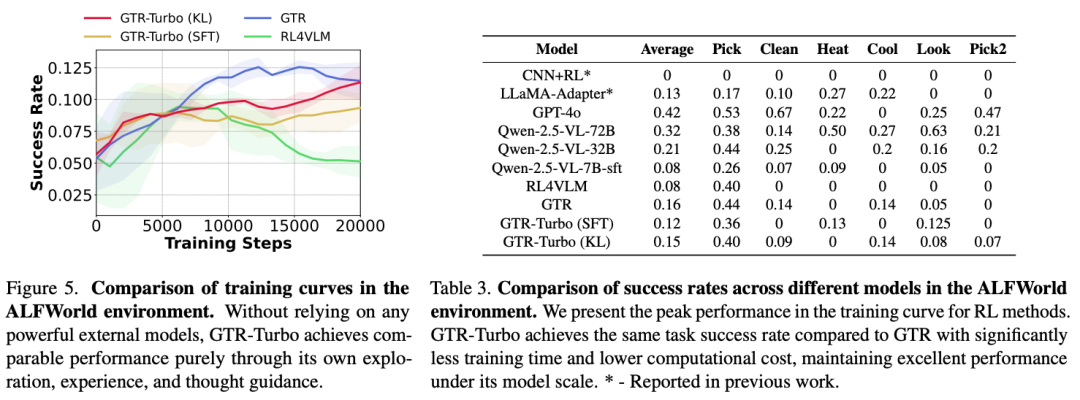
更重要的是,GTR-Turbo通过自我驱动演进的模式取得了巨大的效率提升和成本削减。SFT变体相比GTR已经明显加快,而KL变体更是把训练时间降到了接近纯PPO的程度,最高节省了50%的时间和60%的成本开销。
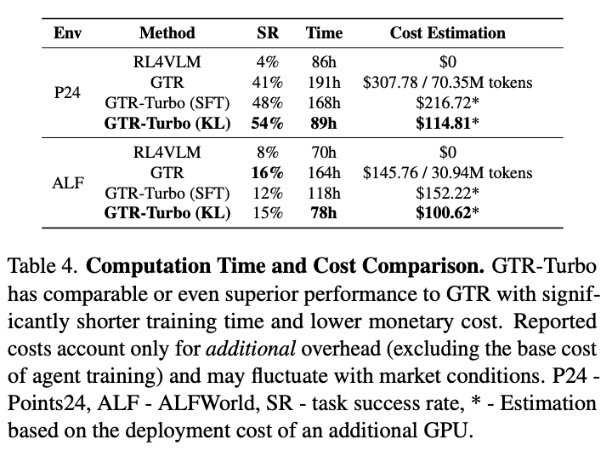
而在部分任务场景中,强大的外部专家模型可能难以获取或者训练数据出于隐私原因无法上传,闭环训练、可以本地部署的GTR-Turbo更具备着无法替代的泛用性优势。
研究意义与展望
GTR-Turbo的意义不仅在于提供了一个高效的VLM Agent训练方案,更在于它揭示了模型自身所蕴含的自监督潜力,证明了通过合理的权重融合机制,模型可以实现“左脚踩右脚”式的性能跃升。
这一创新性的解决方案也为复杂长时任务中构建低成本、高效率的自主进化智能体提供了更多的启发和参考。
论文标题:
GTR-Turbo: Merged Checkpoint is Secretly a Free Teacher for Agentic VLM Training
论文地址:
https://arxiv.org/pdf/2512.13043
作者介绍:
论文第一作者为魏彤,清华大学四年级博士生,研究方向为大模型智能体和强化学习,导师为清华大学教授史元春。合作者为腾讯研究员杨一君、清华大学博士生张常昊、北京大学教授卢宗青。通讯作者为前腾讯AI合伙人&首席专家叶德珩、清华大学教授兴军亮。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓
感兴趣的小伙伴欢迎关注 👉 了解详情

🌟 点亮星标 🌟
科技前沿进展每日见