

有一颗"土豆",正在改变整个AI行业的走向。
这颗"土豆",就是OpenAI下一代旗舰大模型GPT-6的内部代号——Spud(土豆)。
2026年4月9日,OpenAI官方正式确认,GPT-6将于2026年4月14日全球同步发布。这是OpenAI迄今为止最重量级的一次发布,也是继ChatGPT诞生以来,这家公司最被寄予厚望的一次出手。

整个AI圈,都在等这颗"土豆"熟透。
GPT-6的研发周期长达18个月,预训练已于2026年3月17日全面完成,随后经过严格的后训练和安全评估,才最终定档4月14日。
据悉,这次发布的训练投入超20亿美元,动用约10万张英伟达H100 GPU,是OpenAI历史上规模最大的一次训练任务。
相比GPT-5.4,GPT-6在代码生成、逻辑推理和多步智能体任务上性能提升超过40%。用OpenAI自己的话说,这款模型的目标是"让AI第一次具备真正意义上的综合规划能力"。
GPT-6最核心的技术创新,是一套被称为Symphony(交响乐)的全新架构。
这套架构有两个核心设计。第一,原生多模态统一:文本、图像、音频、视频在同一向量空间内处理,不再需要切换插件或调用外部模型,整个交互体验更加连贯流畅。
第二,双系统推理框架:System-1负责快速响应和内容生成,对应人类的"快思考";System-2负责逻辑校验和多步推理,对应人类的"慢思考"。两套系统根据任务复杂度动态切换,兼顾速度与准确性。
在参数规模上,GPT-6总参数量约为5至6万亿,采用混合专家(MoE)架构,实际激活参数约10%,在保持超大规模的同时有效控制了推理成本。
GPT-6另一个令人震惊的指标,是它的上下文窗口扩展至200万Token。
这意味着什么?200万Token大约等于150万字,相当于两部完整的《三体》。你可以一次性把整个代码仓库、几十份合同、一套完整的产品文档塞进去,GPT-6都能完整理解、分析和处理。
对于企业用户来说,这个上下文长度意味着可以真正实现"长程任务自动化"——不再需要分批次处理,AI可以在一个完整的上下文里把一个复杂任务从头做到尾。
GPT-6发布的时间节点,恰好在整个AI军备竞赛最激烈的时刻。
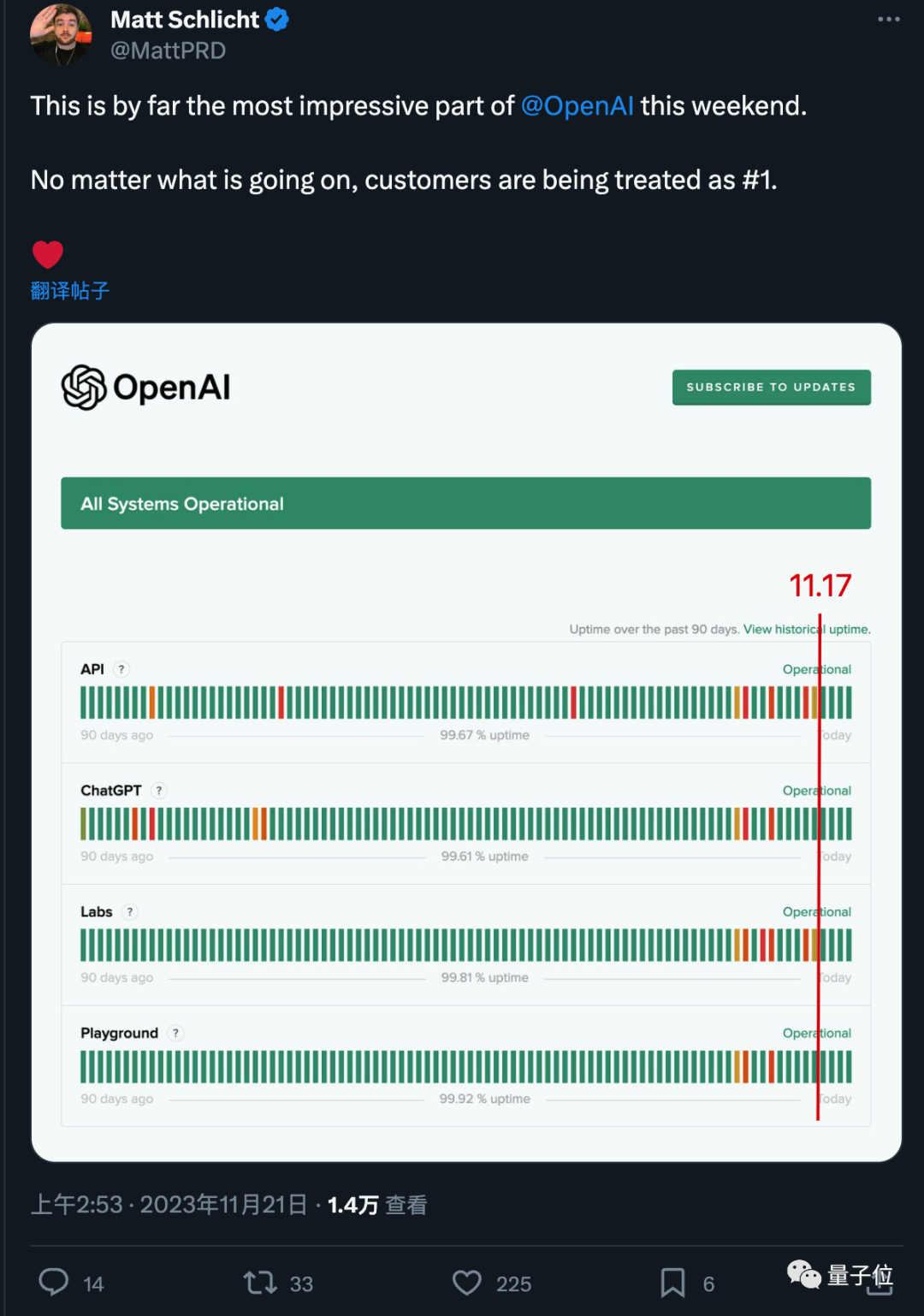
目前,Anthropic的Claude 4系列在编程领域占据显著优势,企业付费市场份额高达73%;谷歌的Gemini 2.5 Pro在推理和代码上也有重大突破,企业心智份额达16.1%。
OpenAI面临着真实的市场压力:尽管ChatGPT仍是全球最知名的AI产品,但在专业用户和企业市场,Claude和Gemini正在步步紧逼。
GPT-6的三大胜负手,业内普遍认为是:原生多模态体验能否超越竞品、编程场景能否反超Claude Code、以及定价策略是否足够有吸引力。
在定价上,OpenAI此次选择了相对保守的策略:每百万Token输入2.5美元,输出12美元,与GPT-5.4基本持平,不打价格战,而是靠性能说话。

在这场三方对决之外,还有一个来自中国的变量不能忽视——DeepSeek。
R2/V4版本据悉同样将在本月发布,凭借MoE架构创新和大幅优化的训练成本,DeepSeek正在打破"顶尖大模型必须烧钱"的逻辑,对所有头部厂商都形成了实质性的成本压力。
这意味着,光靠砸钱训练参数量更大的模型,已经不够了。GPT-6能否真正兑现性能承诺、在实际应用场景中给用户带来质的飞跃,才是关键。

2025年以来,OpenAI的市场地位经历了一定的挑战。GPT-4的光环逐渐褪去,ChatGPT的付费用户增速放缓,而Anthropic、谷歌的围攻步步紧逼。
在这个背景下,GPT-6被内部寄予了极高的期望。据悉,山姆·奥特曼(Sam Altman)曾在内部将GPT-6定位为"通往AGI的最后一公里"——不是夸张的营销语言,而是OpenAI在技术路线上的真实判断。
4月14日,这颗"土豆"将正式揭开面纱。
它能否撑起这个被寄予厚望的称号,能否让OpenAI重新夺回AI领域的领导地位,所有人都在等待答案。