

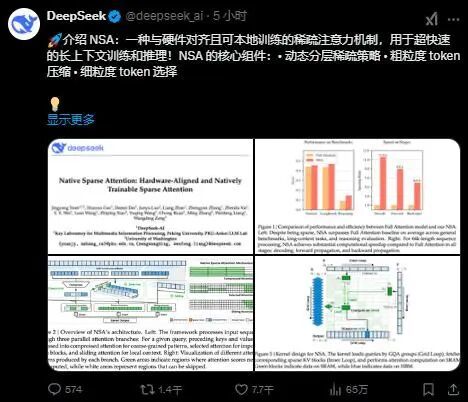
中国AI的下一步,终于有了时间表。
2026年4月10日,DeepSeek创始人梁文锋在内部沟通中首次明确透露:新一代旗舰大模型DeepSeek V4将于4月下旬正式发布。
这个消息迅速在整个AI圈炸开锅。要知道,DeepSeek V3自去年发布以来,以"低成本高性能"的惊人表现颠覆了业界对大模型开发成本的认知,引发全球性的关注和讨论。V4的发布,被许多人视为中国AI继续冲击世界一线的重要信号。

DeepSeek V4不是第一次被提及。此前的几个月里,这个型号已经多次出现在业界传言中,也多次"跳票"。
为什么迟迟未发?梁文锋给出的解释涉及三个方面:国产芯片深度适配、架构重构、以及系统稳定性打磨。
其中,国产芯片适配是最核心的延迟因素。DeepSeek V4将首次实现与华为昇腾等国产算力平台的深度适配,这意味着模型的底层推理引擎、算子优化方案都需要针对非英伟达架构重新设计。这不是简单的移植,而是一次系统级的重构——代价是时间,但价值是长远的战略独立性。

3月29日,DeepSeek服务曾出现长达13小时的中断。业界普遍猜测这次中断与V4的灰度测试或全量部署有关。从那之后,一些用户开始观察到DeepSeek的编码结构更清晰、逻辑严谨度有明显提升,被认为是V4部分能力已悄然上线的信号。

根据目前能够获取到的信息,DeepSeek V4有三个核心技术方向值得重点关注。
第一,万亿参数规模+百万级上下文窗口。 V4将保持万亿级参数规模,同时上下文窗口升级至百万Token级别。百万Token意味着V4可以在一次对话中处理相当于一整本厚厚的技术手册,或者数十篇完整的研究论文——这对企业级文档处理、代码分析和长文本理解是根本性的改变。

第二,长期记忆(LTM)能力突破。 这被认为是V4最重要的技术亮点。传统大模型每次对话都是"无记忆"的,一旦上下文窗口满了,早期信息就会被截断遗忘。V4的LTM机制让模型能够在长期使用中积累和调用历史交互信息,就像人类的记忆系统一样——短期记忆和长期记忆协同工作,而不是每次清空重来。

第三,华为昇腾深度适配+开源Apache 2.0协议。 V4将继续遵循Apache 2.0协议开源,企业可以自主部署。更重要的是,对国产算力的深度优化意味着国内企业在使用V4时,不再必须依赖英伟达GPU,昇腾等国产芯片的使用成本和部署可行性都将显著改善。

V4的发布不只是一个模型版本更新,它已经对整个AI产业链产生了可感知的预期影响。
据悉,阿里巴巴、字节跳动、腾讯等国内科技巨头已经预订了数十万片新一代AI算力芯片,计划通过云服务的形式提供DeepSeek V4,并将其集成到各自的AI产品体系中。

受此影响,新型AI算力芯片的市场价格近期上涨了约20%。这个数字背后,是整个产业在为V4的发布做规模化部署准备。
同时,梁文锋透露,DeepSeek正在专门组建产品团队,并发布了针对Agent方向的"模型策略产品经理"职位招聘。这标志着DeepSeek的发展战略开始从"技术演示"向产品化和商业化转型——这对DeepSeek的长期竞争力是一个非常重要的信号。

DeepSeek V4的发布时间节点相当微妙。
就在同一个月,OpenAI的GPT-6也在坊间盛传即将发布,代号"Spud"(土豆),据称性能提升超过40%,支持200万Token上下文。两款全球顶级大模型在同一时间窗口亮相,这对整个AI行业来说是罕见的"双雄对决"时刻。
从技术路线上看,两者的差异非常有代表性:GPT-6走的是大规模算力堆叠+商业闭源路线,而DeepSeek V4走的是效率优先+开源普惠路线。前者的优势在于资本壁垒和用户生态,后者的优势在于可访问性和生态自主性。
这两种路线,代表的不只是技术选择,更是两套完全不同的商业哲学和AI产业观。
从更宏观的视角来看,DeepSeek V4的意义超越了一款模型的本身。
它代表的是:中国AI团队已经具备在最顶尖的技术层面与全球第一梯队正面竞争的能力。不是以"低成本替代品"的身份,而是以真正的技术创新者的身份——在长期记忆、国产算力适配、开源生态等关键方向上,走出了一条与美国主流路线不同但同样有竞争力的道路。
V3让世界重新认识了中国AI的潜力,V4将要做的,是把这种潜力真正转化为持续的、可复制的竞争优势。
4月下旬,等待揭晓。